一个围绕热管理材料构建的科研工程平台,整合 MCE、ECE、BCE、OCE、ELCE、TECS、PCET、TEG、TCX 等材料数据模型,提供前后台数据管理、CIF/结构数据查看、Materials Project 信息补全,以及基于 LangGraph 的材料候选筛选与发现智能体。
PROJECT · Agent
面向固态制冷与热电材料的数据库、可视化检索与多智能体发现工作流
2026-04-26 · Agent
一个围绕热管理材料构建的科研工程平台,整合 MCE、ECE、BCE、OCE、ELCE、TECS、PCET、TEG、TCX 等材料数据模型,提供前后台数据管理、CIF/结构数据查看、Materials Project 信息补全,以及基于 LangGraph 的材料候选筛选与发现智能体。
tmmd.csu.edu.cn
Open link
tmmd.csu.edu.cn

热管理材料研究里,数据往往散落在论文、Materials Project、CSV 表格、CIF 文件和实验记录之间。真正做材料筛选时,需要同时回答几个问题:这个材料是否稳定?相变温度是否接近目标窗口?电卡或磁卡效应是否足够强?有没有结构文件?是否适合进入下一轮计算?
这个项目的目标,是把这些分散的信息组织成一个可检索、可维护、可扩展的材料基因数据库,并在此基础上接入智能体工作流,让系统可以从自然语言研究目标出发,辅助完成候选材料召回、筛选、评分和报告生成。
 系统分成四层:
系统分成四层:
User/Admin Web
-> Spring Boot API
-> MySQL + Redis + CIF Storage
-> FastAPI Agent Service
-> LangGraph Discovery Workflow
-> RAG / TMMD DB / Materials Project
-> Candidate Screening + Scoring + Report数据库围绕热管理材料的关键物理机制设计,覆盖固态制冷与热电方向的多类数据:
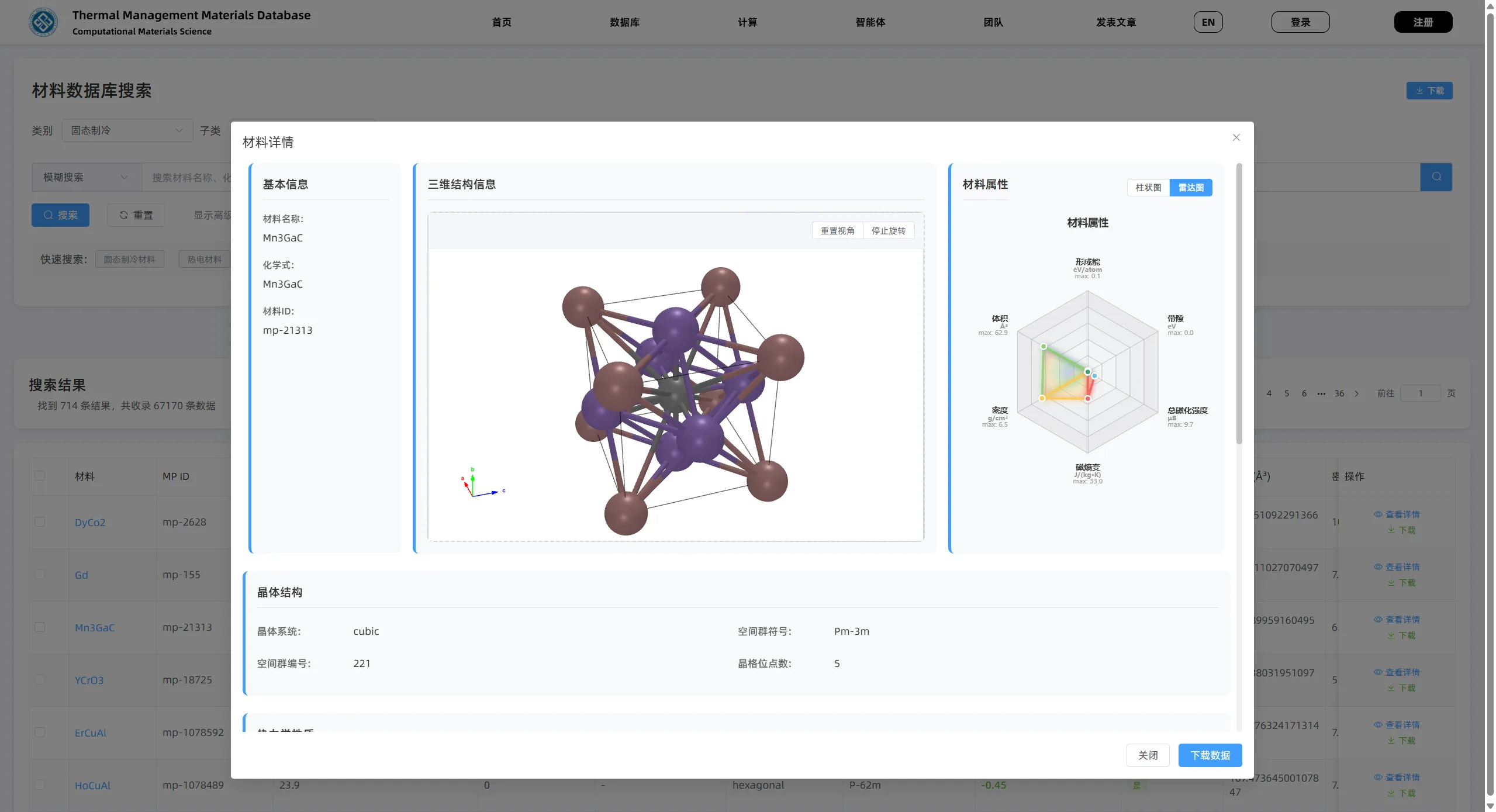
以电卡材料为例,数据库不仅存储材料名、化学式、文献来源和 DOI,还记录铁电相/顺电相、双相 MP ID、居里温度、电卡熵变、电卡温变、电场强度、自发极化、剩余极化、矫顽场、介电常数、压电模量、能量凸包、形成能、带隙和 CIF 路径等字段。
这些字段让材料不只是“表格里的一行”,而是一个可以被搜索、比较、解释和继续计算的研究对象。
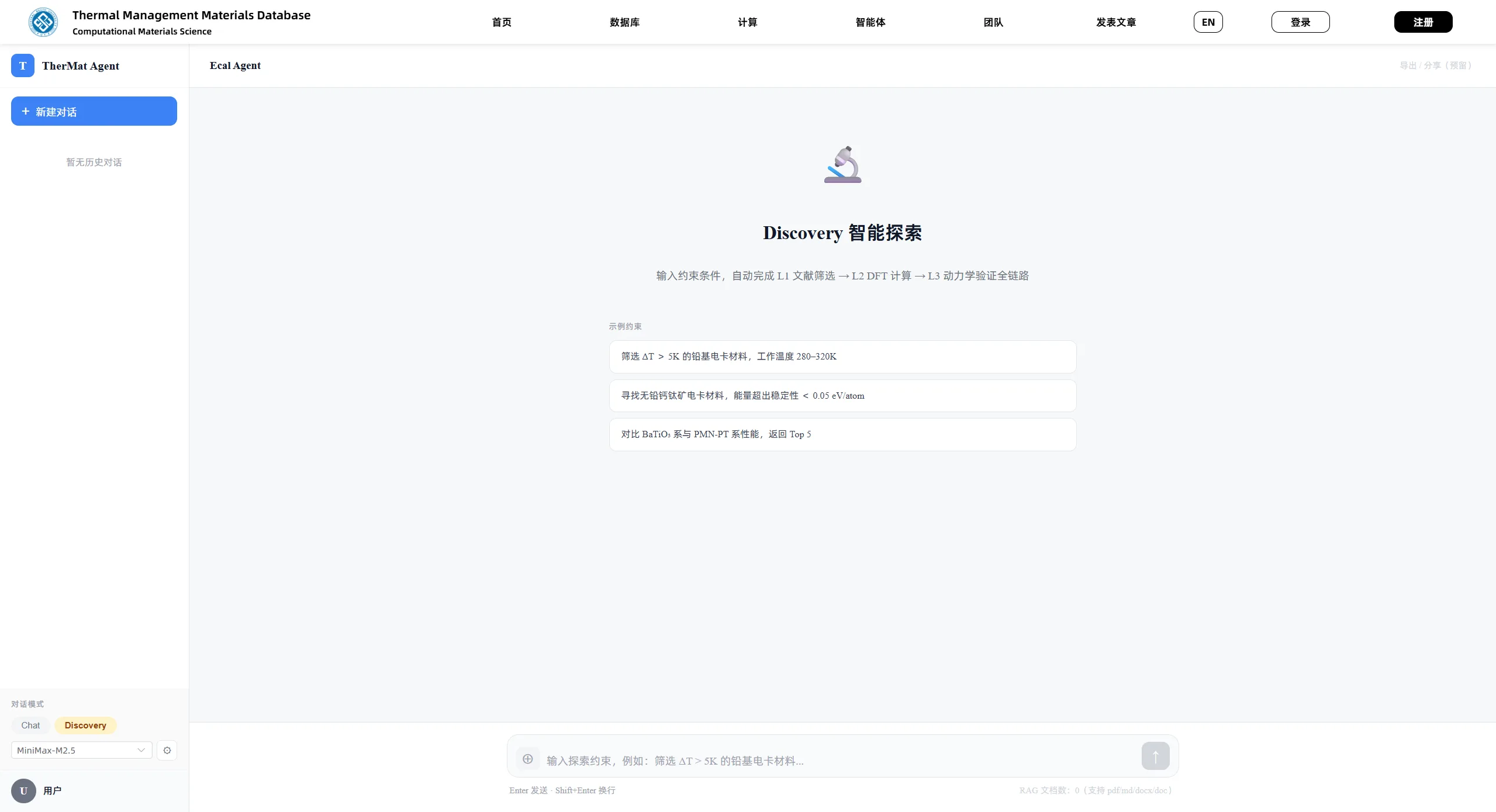
智能体的 discovery 模式面向材料候选发现。用户可以输入自然语言目标,例如:
筛选室温附近、高 ΔT、低工作电场、不要含铅的电卡材料。
系统会把这个目标解析为结构化约束,然后从三类来源召回候选:
候选材料进入分层流程:
这个项目的核心价值不在于单个页面或单个 API,而在于把科研材料数据平台和智能体工作流连接起来:
我没有把智能体做成一个“聊天窗口套壳”,而是把它放在材料发现流程中。它需要知道数据从哪里来、候选为什么被选中、哪些指标支持它进入下一轮、哪些风险需要研究者判断。
另一个关键决定是保留 human-in-the-loop gate。材料发现不是纯自动化推荐,尤其在候选材料进入高成本计算前,需要让研究者参与决策。智能体负责整理证据、提出建议和生成报告,人负责判断研究方向是否值得继续。
后续我希望继续完善三件事: