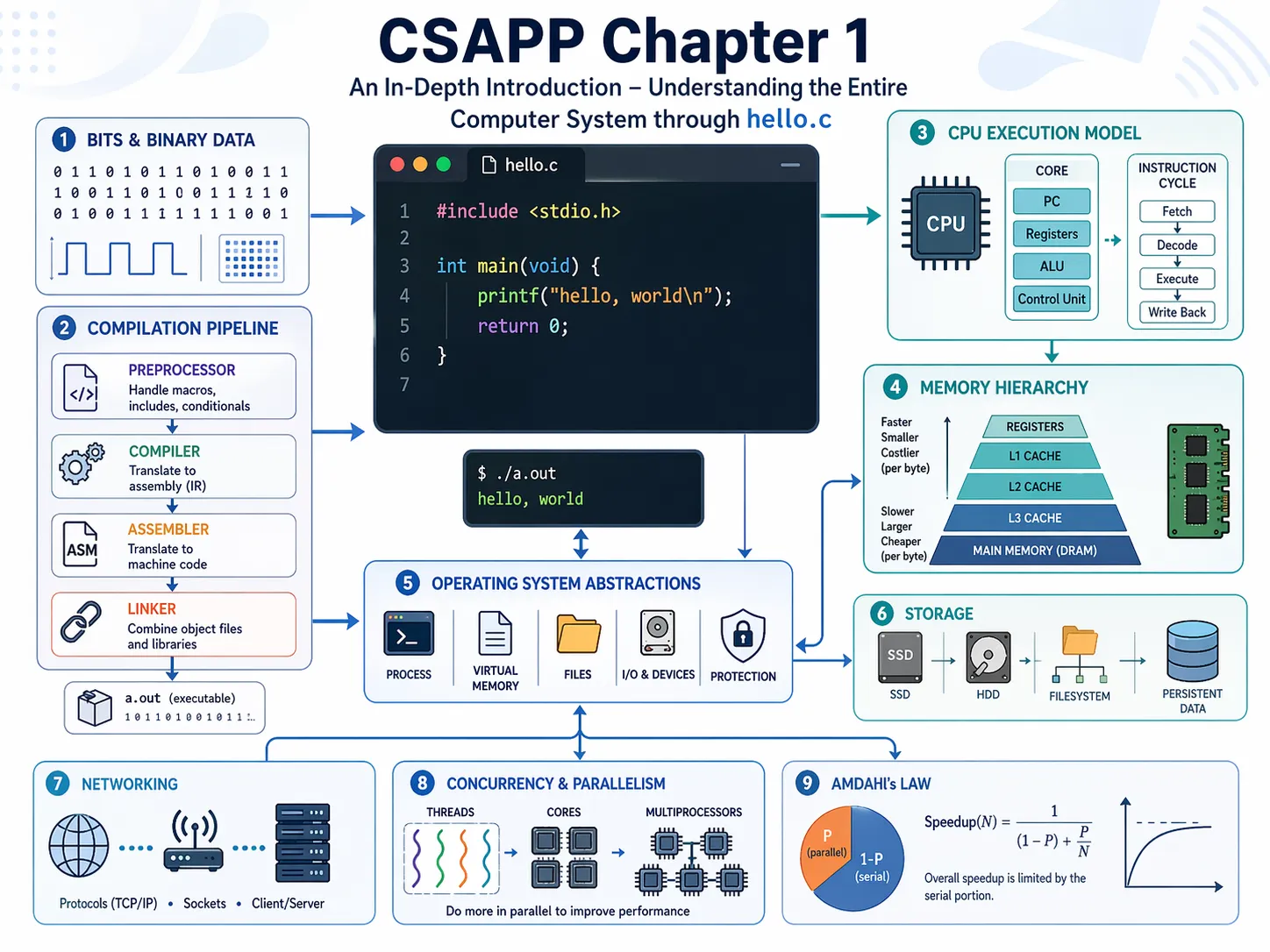
写在前面:为什么一个 hello world 可以讲完整台计算机
很多人第一次看到 CSAPP 第 1 章,会以为它只是一本系统书的开场白:从 hello.c 开始,讲一点编译器,讲一点 CPU,讲一点操作系统,最后再提一下网络和并发。
但真正厉害的地方在这里:hello.c 不是例子,它是一条主线。
你写下这几行代码:
#include <stdio.h>
int main(void) {
printf("hello, world\n");
return 0;
}然后在终端输入:
gcc -o hello hello.c
./hello屏幕上出现:
hello, world看起来像魔法。实际上,中间发生了至少这些事:
- 你写的字符被编码成字节,最终都只是 0 和 1。
- 编译系统把 C 代码翻译成机器能执行的指令。
- shell 请求操作系统加载可执行文件。
- 操作系统创建进程,并把程序映射到虚拟地址空间。
- CPU 从内存取指令,解释指令,执行计算和跳转。
- 数据在磁盘、内存、缓存、寄存器、显示设备之间不断搬运。
printf背后通过库函数和系统调用,把字节写到终端。- 如果程序在远程机器上运行,网络也只是另一种 I/O 设备。
这篇文章的目标很简单:把这条链路讲到你能“脑内单步调试”。
读完以后,你应该不只是知道 hello.c 会打印一句话,而是知道:
- 为什么所有信息本质上都是位,但同一串位能表示完全不同的东西。
- 为什么编译不是一步完成,而是预处理、编译、汇编、链接的流水线。
- 为什么懂编译系统能帮你写出更快、更安全、更少坑的程序。
- CPU 执行程序时究竟在“读什么、改什么、跳到哪里”。
- 为什么缓存是性能的灵魂,为什么程序的访问模式会影响速度。
- 操作系统到底提供了哪些“假象”:进程、虚拟内存、文件。
- 并发和并行差在哪里,Amdahl 定律为什么会让很多优化梦碎。
参考原文来自 Hansimov 整理的 CSAPP 中文 GitBook 第 1 章相关页面:
下面开始。
1. 信息就是位,但位本身没有意义
计算机里所有东西都是位,也就是 0 和 1。
但是这句话容易让人误会。更准确地说:
计算机只保存位;人和程序通过上下文解释位。
比如同样一个字节:
01000001如果按无符号整数解释,它是 65。
如果按 ASCII 字符解释,它是 'A'。
如果它出现在机器指令里,它可能是某条指令的一部分。
如果它出现在图片文件里,它可能参与表示某个像素或压缩块。
位没有天然含义,含义来自上下文。
用代码看字节和字符
下面这段 C 程序会把字符串里的每个字符按十六进制打印出来:
#include <stdio.h>
int main(void) {
const char *s = "hello\n";
for (int i = 0; s[i] != '\0'; i++) {
printf("char=%c, decimal=%d, hex=0x%02x\n", s[i], s[i], (unsigned char)s[i]);
}
return 0;
}可能输出:
char=h, decimal=104, hex=0x68
char=e, decimal=101, hex=0x65
char=l, decimal=108, hex=0x6c
char=l, decimal=108, hex=0x6c
char=o, decimal=111, hex=0x6f
char=
, decimal=10, hex=0x0a这里最值得注意的是换行符。你看不见它,但它也是一个字节,值是 10,十六进制是 0x0a。
所以源文件不是“文字”这么抽象的东西。它在磁盘上就是一串字节。编辑器把这些字节解释成字符,编译器再把这些字符解释成 C 程序。
文本文件和二进制文件的区别
所谓文本文件,本质上是“可以按照某种字符编码解释成文本的字节序列”。所谓二进制文件,则是不适合直接按文本方式解释的字节序列。
注意,不是文本文件才由 0 和 1 组成,二进制文件才由 0 和 1 组成。两者都由 0 和 1 组成。区别在于解释方式。
你可以用 xxd 或类似工具观察文件内容:
printf 'hello\n' > hello.txt
xxd hello.txt输出类似:
00000000: 6865 6c6c 6f0a hello.68 65 6c 6c 6f 0a 就是 hello\n 的字节表示。
这就是系统世界里的第一条铁律:没有“神秘的高级对象”,只有字节,以及解释字节的规则。
2. 从 hello.c 到 hello:编译系统的四段旅程
C 程序不能直接运行。CPU 执行的是机器指令,不是 C 语句。
所以:
printf("hello, world\n");必须被翻译成某种机器能执行的指令序列。
在 Unix/Linux 风格的系统里,典型命令是:
gcc -o hello hello.c这个命令看起来只有一步,其实背后大致分成四个阶段:
hello.c --预处理--> hello.i --编译--> hello.s --汇编--> hello.o --链接--> hello2.1 预处理:把宏和头文件展开
预处理器主要处理以 # 开头的指令,比如:
#include <stdio.h>
#define N 10你可以这样只运行预处理阶段:
gcc -E hello.c -o hello.ihello.i 仍然是 C 代码,只是很多头文件内容、宏替换结果已经被塞进去了。它通常会比原始文件大得多。
举个极简例子:
#define SQUARE(x) ((x) * (x))
int main(void) {
return SQUARE(3 + 1);
}预处理后关键部分会变成类似:
int main(void) {
return ((3 + 1) * (3 + 1));
}这里有个常见坑:宏不是函数,它是文本级替换。
看这个危险写法:
#define BAD_SQUARE(x) x * x
int main(void) {
return BAD_SQUARE(3 + 1);
}展开后是:
return 3 + 1 * 3 + 1;结果是 7,不是 16。
这就是为什么系统级程序员要理解预处理:它不是“编译器前的小杂活”,它能直接制造 bug。
2.2 编译:从 C 到汇编
编译阶段把预处理后的 C 程序翻译成汇编语言:
gcc -S hello.i -o hello.s你也可以直接:
gcc -S hello.c -o hello.s汇编语言是机器指令的文本表示。它仍然给人看,但已经非常接近机器。
一个简化后的 main 可能长这样:
main:
subq $8, %rsp
leaq .LC0(%rip), %rdi
call puts
movl $0, %eax
addq $8, %rsp
ret不用怕汇编。先抓住几个关键词:
%rsp:栈指针寄存器,跟函数调用栈有关。%rdi:在 x86-64 System V 调用约定里,常用于传第一个参数。call puts:调用函数。%eax:常用于保存返回值。ret:函数返回。
也就是说,C 里的 printf("hello, world\n") 最终会变成一堆操作寄存器、内存和控制流的低级动作。
2.3 汇编:从汇编文本到目标文件
汇编器把 .s 文件翻译成机器指令,并打包成目标文件:
gcc -c hello.s -o hello.ohello.o 是二进制文件。你用普通文本编辑器打开,会看到乱码。
但它还不是完整可执行文件。原因是:程序里调用了库函数,比如 printf 或 puts,这些函数的实现不在你的 hello.c 里。
此时目标文件里可能只有一句话:
我这里要调用 printf,但它在哪里,链接时再说。这个“以后再说”的能力,叫重定位。
2.4 链接:把多个目标文件和库合成可执行文件
链接器负责把你的目标文件、标准库代码、启动代码等拼成最终可执行文件:
gcc hello.o -o hello可以把链接理解成“组装工程”:
hello.o里有你写的main。- C 标准库里有
printf。 - 系统启动代码知道如何在程序启动时调用
main。 - 链接器把这些碎片组合起来,修正地址引用,产出可执行文件。
链接阶段也是很多 C/C++ 程序员痛苦的源头。比如:
// math_demo.c
#include <math.h>
#include <stdio.h>
int main(void) {
printf("%f\n", sqrt(2.0));
return 0;
}在一些 Unix 系统上,直接编译可能会失败:
gcc math_demo.c -o math_demo需要显式链接数学库:
gcc math_demo.c -o math_demo -lm这不是 C 语法问题,而是链接问题。
3. 为什么理解编译系统很重要
有些知识看似底层,但会直接影响你写上层代码的能力。编译系统就是这样。
3.1 它帮你理解性能
看这两个函数:
int sum_a(int *arr, int n) {
int sum = 0;
for (int i = 0; i < n; i++) {
sum += arr[i];
}
return sum;
}
int sum_b(int *arr, int n) {
int sum = 0;
for (int i = 0; i < n; i += 4) {
sum += arr[i];
sum += arr[i + 1];
sum += arr[i + 2];
sum += arr[i + 3];
}
return sum;
}在某些条件下,sum_b 可能更快,因为它减少循环控制开销,也可能帮助编译器做更好的优化。但它也可能因为越界、分支处理、编译器自动优化等因素变得没那么直观。
现代编译器很强,但不是魔法师。你理解它生成什么样的机器代码,就更容易知道优化是否真的有效。
3.2 它帮你定位链接错误
比如你写了两个文件:
// add.c
int add(int a, int b) {
return a + b;
}// main.c
#include <stdio.h>
int add(int a, int b);
int main(void) {
printf("%d\n", add(2, 3));
return 0;
}正确编译:
gcc main.c add.c -o app如果你只编译 main.c:
gcc main.c -o app会得到类似 undefined reference to add 的错误。
这不是 main.c 看不懂 add 的声明,而是链接器找不到 add 的实现。
3.3 它帮你理解安全漏洞
比如经典缓冲区溢出:
#include <stdio.h>
#include <string.h>
int main(void) {
char name[8];
strcpy(name, "this string is too long");
printf("%s\n", name);
return 0;
}name 只有 8 个字节,但 strcpy 不检查边界。多出来的字节会覆盖旁边的内存,可能破坏栈上的数据,甚至在某些条件下改变控制流。
你只有理解内存布局、栈、函数调用和机器级控制流,才会真正明白这类漏洞为什么危险。
4. 程序运行时,CPU 到底在做什么
编译完成后,磁盘上有了可执行文件 hello。
你在 shell 里输入:
./helloshell 会判断:这不是内置命令,那就把它当成可执行文件加载运行。
但 shell 自己不会直接操控磁盘、内存、CPU 和显示器。它会请求操作系统帮忙。
4.1 典型硬件模型
一个经典系统可以粗略看成这样:
键盘/鼠标/磁盘/网卡/显示器
|
I/O 总线
|
主存 DRAM
|
CPU
┌───────────────┐
│ PC 程序计数器 │
│ 寄存器文件 │
│ ALU 算术逻辑单元│
└───────────────┘几个核心部件:
- 总线:在各部件之间搬运字节。
- I/O 设备:键盘、显示器、磁盘、网卡等外部世界入口。
- 主存:程序运行时放代码和数据的地方。
- CPU:执行指令的引擎。
- PC:程序计数器,保存下一条要执行指令的地址。
- 寄存器:CPU 内部很小但很快的存储。
- ALU:做算术和逻辑运算。
4.2 CPU 的简单执行模型
先忽略现代 CPU 的复杂优化。站在指令集架构的抽象层看,CPU 不断重复:
取指令 -> 解释指令 -> 执行动作 -> 更新 PC动作大致包括:
- 加载:从内存读数据到寄存器。
- 存储:从寄存器写数据到内存。
- 运算:用 ALU 对寄存器里的值做加减与或等操作。
- 跳转:修改 PC,让下一条指令来自另一个地址。
用伪代码表示:
while (power_on) {
instruction = memory[PC]
PC = PC + instruction.length
execute(instruction)
}当然,真实处理器会流水线、乱序执行、分支预测、缓存预取,但它对程序员暴露出来的效果仍然像上面的简单模型。
这就是抽象的力量:底层可以极其复杂,上层仍然看到一个稳定模型。
4.3 运行 hello 时的数据搬运
./hello 的生命周期可以拆成几步:
- shell 读取键盘输入,把字符
.、/、h、e、l、l、o放入内存。 - 你按下回车,shell 知道命令输入结束。
- shell 通过系统调用请求内核加载
hello。 - 内核把可执行文件中的代码和数据从磁盘加载到内存。
- CPU 开始执行
hello的机器指令。 - 程序调用库函数,最终请求系统把
hello, world\n写到标准输出。 - 字节经过内核和终端设备,显示在屏幕上。
所以这句输出:
hello, world不是“程序直接写屏幕”。更像是:
用户程序 -> C 标准库 -> 系统调用 -> 内核 -> 设备驱动/终端 -> 显示设备5. 性能的本质:系统大部分时间都在搬数据
hello 程序没有做复杂计算,但它已经发生了多次复制:
- 可执行文件从磁盘复制到主存。
- 指令从主存复制到 CPU。
- 字符串从磁盘复制到主存。
- 字符串从主存复制到寄存器。
- 字符串从用户程序复制到内核缓冲区。
- 字符串最终被送到终端设备。
系统性能的很大一部分,就取决于这些数据搬运有多快。
5.1 为什么需要缓存
存储设备有一个残酷规律:
越快 -> 越小 -> 越贵
越慢 -> 越大 -> 越便宜寄存器很快,但只能放极少数据。
内存大得多,但比寄存器慢。
磁盘更大,但比内存慢很多。
如果 CPU 每次都直接等内存或磁盘,性能会崩。
所以系统加入缓存:
寄存器
↓
L1 Cache
↓
L2 Cache
↓
L3 Cache
↓
主存 DRAM
↓
SSD / 磁盘
↓
远程存储缓存的思想是:把近期可能用到的数据,提前放到更快的小存储里。
5.2 局部性:缓存为什么有效
缓存能有效,是因为程序通常有局部性。
时间局部性:
如果一个数据刚被访问过,它很可能很快再次被访问。
空间局部性:
如果一个地址被访问,它附近的地址很可能也会被访问。
看这个例子:
int sum_row_major(int rows, int cols, int a[rows][cols]) {
int sum = 0;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
sum += a[i][j];
}
}
return sum;
}C 语言二维数组按行连续存储。a[i][0]、a[i][1]、a[i][2] 在内存里挨得很近,所以这段代码空间局部性很好。
再看这个:
int sum_column_major(int rows, int cols, int a[rows][cols]) {
int sum = 0;
for (int j = 0; j < cols; j++) {
for (int i = 0; i < rows; i++) {
sum += a[i][j];
}
}
return sum;
}这段按列访问。每次跳过一整行,缓存刚加载的一批相邻数据可能用不上,性能通常更差。
5.3 一个可跑的缓存实验
下面的程序用一维数组模拟二维矩阵,比较按行访问和按列访问的耗时。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 4096
static int *matrix;
static double now_seconds(void) {
return (double)clock() / CLOCKS_PER_SEC;
}
long long sum_by_rows(void) {
long long sum = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
sum += matrix[i * N + j];
}
}
return sum;
}
long long sum_by_cols(void) {
long long sum = 0;
for (int j = 0; j < N; j++) {
for (int i = 0; i < N; i++) {
sum += matrix[i * N + j];
}
}
return sum;
}
int main(void) {
matrix = malloc((size_t)N * N * sizeof(int));
if (matrix == NULL) {
return 1;
}
for (int i = 0; i < N * N; i++) {
matrix[i] = i & 255;
}
double t1 = now_seconds();
long long a = sum_by_rows();
double t2 = now_seconds();
long long b = sum_by_cols();
double t3 = now_seconds();
printf("row sum=%lld, time=%.3fs\n", a, t2 - t1);
printf("col sum=%lld, time=%.3fs\n", b, t3 - t2);
free(matrix);
return 0;
}编译运行:
gcc -O2 cache_demo.c -o cache_demo
./cache_demo按列访问通常会慢很多。不是因为加法变慢了,而是因为内存访问模式更糟。
这就是为什么 CSAPP 后面会花大量篇幅讲存储器层次结构和程序优化:真正影响性能的,经常不是你写了几个 +,而是数据如何在层次结构里流动。
6. 操作系统:站在应用程序和硬件之间的管理者
应用程序不能随便碰硬件。
如果任何程序都能直接读写磁盘、操作内存、控制网卡,那系统很快就会混乱甚至崩溃。
所以操作系统夹在应用程序和硬件之间:
应用程序
↓
操作系统
↓
硬件它主要做两件事:
- 防止应用程序滥用硬件。
- 给应用程序提供简单一致的抽象。
CSAPP 第 1 章强调三个核心抽象:
- 进程:对 CPU、内存、I/O 的抽象。
- 虚拟内存:对主存和磁盘的抽象。
- 文件:对 I/O 设备的抽象。
6.1 进程:正在运行的程序
程序是磁盘上的文件。进程是运行中的程序。
当你运行:
./hello操作系统会创建一个进程。这个进程拥有自己的上下文,包括:
- 程序计数器 PC 当前在哪里。
- 各个寄存器当前是什么值。
- 虚拟地址空间里有哪些代码、数据、堆、栈。
- 打开的文件描述符有哪些。
现代系统可以同时运行很多进程。即使单核 CPU 一次只能真正执行一个进程,操作系统也会快速切换,让你感觉它们同时运行。
这个切换叫上下文切换。
简化过程:
保存进程 A 的寄存器、PC 等状态
恢复进程 B 的寄存器、PC 等状态
CPU 开始执行进程 B用一个程序感受进程:
#include <stdio.h>
#include <unistd.h>
int main(void) {
printf("before fork, pid=%d\n", getpid());
pid_t pid = fork();
if (pid == 0) {
printf("child process, pid=%d\n", getpid());
} else {
printf("parent process, pid=%d, child=%d\n", getpid(), pid);
}
return 0;
}编译运行:
gcc fork_demo.c -o fork_demo
./fork_demofork 会创建一个子进程。父子进程从同一个位置继续执行,但 fork 的返回值不同。
这就是操作系统给你的强大能力:复制一个正在运行的控制流。
6.2 线程:同一个进程里的多条执行流
进程可以包含多个线程。线程共享同一个进程的代码和全局数据,但每个线程有自己的执行流。
一个简单的 pthread 示例:
#include <pthread.h>
#include <stdio.h>
void *worker(void *arg) {
int id = *(int *)arg;
printf("hello from thread %d\n", id);
return NULL;
}
int main(void) {
pthread_t t1;
pthread_t t2;
int a = 1;
int b = 2;
pthread_create(&t1, NULL, worker, &a);
pthread_create(&t2, NULL, worker, &b);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}编译:
gcc thread_demo.c -o thread_demo -pthread线程比进程更轻量,共享数据更方便,但也更容易踩并发 bug,比如数据竞争。
6.3 虚拟内存:每个进程都以为自己独占内存
虚拟内存给每个进程一种幻觉:
整片地址空间都是我的。一个 Linux 进程的虚拟地址空间大致可以想成:
高地址
┌────────────────────┐
│ 内核虚拟内存 │
├────────────────────┤
│ 用户栈 │ 函数调用、局部变量
├────────────────────┤
│ 共享库 │ libc、动态库
├────────────────────┤
│ 堆 │ malloc/free
├────────────────────┤
│ 程序数据 │ 全局变量、静态变量
├────────────────────┤
│ 程序代码 │ 机器指令
└────────────────────┘
低地址看这个程序:
#include <stdio.h>
#include <stdlib.h>
int global_value = 42;
int main(void) {
int stack_value = 7;
int *heap_value = malloc(sizeof(int));
if (heap_value == NULL) {
return 1;
}
*heap_value = 99;
printf("code address: %p\n", (void *)&main);
printf("global address: %p\n", (void *)&global_value);
printf("heap address: %p\n", (void *)heap_value);
printf("stack address: %p\n", (void *)&stack_value);
free(heap_value);
return 0;
}你会看到不同变量位于不同区域。每次运行地址还可能变化,这是地址空间布局随机化等机制的结果。
虚拟内存的妙处在于:
- 每个进程有自己的地址空间,互不干扰。
- 操作系统可以把暂时不用的内容放到磁盘。
- 内存保护变得可能,用户程序不能随便访问内核空间。
- 加载可执行文件、共享库、内存映射文件都有统一机制。
6.4 文件:一切 I/O 都可以看成字节流
Unix 世界里有个非常漂亮的思想:很多东西都可以看成文件。
- 普通磁盘文件是文件。
- 键盘输入是文件。
- 终端输出是文件。
- 网络连接可以通过文件描述符操作。
底层不同,接口相似。
看一个不用 printf、直接用 Unix I/O 的例子:
#include <unistd.h>
int main(void) {
const char message[] = "hello through write\n";
write(1, message, sizeof(message) - 1);
return 0;
}这里 1 是标准输出的文件描述符。
write 的意思是:把这段字节写到文件描述符 1 指向的对象。它可能是终端,可能被重定向到文件,也可能被管道接走。
运行:
./a.out
./a.out > out.txt
cat out.txt程序不需要知道输出终点到底是屏幕还是文件。这就是抽象的价值。
7. 网络:从系统角度看,网卡也是 I/O 设备
站在单机视角,网络并不神秘。
当程序把一串字节写到网络连接时,系统把数据从内存复制到网络适配器,再由网络传到另一台机器。
当程序从网络读取数据时,系统把来自网卡的数据复制到内存。
所以网络也可以放进同一套模型:
内存中的字节
↓
操作系统网络协议栈
↓
网卡
↓
网络
↓
另一台机器的网卡
↓
另一台机器的内存一个极简 TCP 客户端示例:
#include <arpa/inet.h>
#include <stdio.h>
#include <string.h>
#include <sys/socket.h>
#include <unistd.h>
int main(void) {
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0) {
return 1;
}
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(80);
inet_pton(AF_INET, "93.184.216.34", &server.sin_addr);
if (connect(fd, (struct sockaddr *)&server, sizeof(server)) < 0) {
close(fd);
return 1;
}
const char request[] = "GET / HTTP/1.0\r\nHost: example.com\r\n\r\n";
write(fd, request, sizeof(request) - 1);
char buf[1024];
ssize_t n;
while ((n = read(fd, buf, sizeof(buf))) > 0) {
write(1, buf, (size_t)n);
}
close(fd);
return 0;
}这个程序里,socket 返回的 fd 也是一个文件描述符。你可以对它 read 和 write。
所以从 Unix I/O 的角度看:
读本地文件、读键盘、读网络连接都可以统一成:
read(fd, buffer, n);这就是“文件是 I/O 抽象”的威力。
8. Amdahl 定律:为什么局部优化经常没有想象中猛
Amdahl 定律讨论一个朴素问题:
如果我把系统某一部分加速了,整体能快多少?
设:
- 原始总耗时是
Told。 - 可优化部分占比是
alpha。 - 这部分加速了
k倍。
那么新耗时:
Tnew = Told * ((1 - alpha) + alpha / k)整体加速比:
S = Told / Tnew = 1 / ((1 - alpha) + alpha / k)一个直觉例子
假设一个程序总耗时 100 秒,其中 60 秒在排序,40 秒在其他逻辑。
你把排序优化到原来的 3 倍快。
新耗时:
40 + 60 / 3 = 60 秒整体加速比:
100 / 60 = 1.67 倍你把一个大模块加速了 3 倍,但整体只快了 1.67 倍。
原因很简单:没优化的那 40 秒还在那里。
用 JavaScript 算 Amdahl 定律
function amdahl(alpha, k) {
return 1 / ((1 - alpha) + alpha / k);
}
console.log(amdahl(0.6, 3)); // 1.666...
console.log(amdahl(0.8, 10)); // 3.571...
console.log(amdahl(0.95, 100)); // 16.806...最扎心的是极限情况:如果某部分占比是 alpha,哪怕你把它优化到不耗时间,最大加速比也是:
Smax = 1 / (1 - alpha)如果你只能优化 80% 的部分,理论上最多也就:
1 / (1 - 0.8) = 5 倍这解释了很多性能优化里的现实:
- 优化热点前,必须先测量。
- 优化一个很小的函数,即使快 100 倍,整体也可能没感觉。
- 要获得数量级提升,通常要改变系统大部分路径,甚至换算法、换架构。
9. 并发和并行:同时处理,不等于更快
并发和并行经常被混用,但它们不是一回事。
并发:系统中有多个活动同时处于进行中。
并行:多个活动真的在同一时刻执行,通常目的是更快。
单核 CPU 也可以并发。它快速切换任务,让你感觉浏览器、音乐播放器、编辑器都在运行。
多核 CPU 可以并行。不同核心真的同时执行不同线程。
9.1 线程级并发
比如 Web 服务器同时处理多个请求:
请求 A:读数据库
请求 B:解析 JSON
请求 C:等待网络
请求 D:渲染页面即使其中某些请求在等待 I/O,其他请求也可以继续推进。
但并发会引入共享状态问题:
#include <pthread.h>
#include <stdio.h>
long counter = 0;
void *worker(void *arg) {
(void)arg;
for (int i = 0; i < 1000000; i++) {
counter++;
}
return NULL;
}
int main(void) {
pthread_t a;
pthread_t b;
pthread_create(&a, NULL, worker, NULL);
pthread_create(&b, NULL, worker, NULL);
pthread_join(a, NULL);
pthread_join(b, NULL);
printf("counter=%ld\n", counter);
return 0;
}你可能期待输出 2000000,但实际未必。因为 counter++ 不是原子操作,它大致包含:
读 counter
加 1
写回 counter两个线程交错执行时,更新可能丢失。
修复方式之一是加锁:
#include <pthread.h>
#include <stdio.h>
long counter = 0;
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void *worker(void *arg) {
(void)arg;
for (int i = 0; i < 1000000; i++) {
pthread_mutex_lock(&lock);
counter++;
pthread_mutex_unlock(&lock);
}
return NULL;
}
int main(void) {
pthread_t a;
pthread_t b;
pthread_create(&a, NULL, worker, NULL);
pthread_create(&b, NULL, worker, NULL);
pthread_join(a, NULL);
pthread_join(b, NULL);
printf("counter=%ld\n", counter);
return 0;
}但锁也有成本。并发不是免费午餐。
9.2 指令级并行
现代 CPU 并不是傻傻地一条指令完全执行完再执行下一条。
它会用流水线把指令执行拆成多个阶段,比如:
取指 -> 译码 -> 执行 -> 访存 -> 写回不同指令可以处于不同阶段,就像工厂流水线。
更高级的 CPU 还能乱序执行、分支预测、同时发射多条指令。这些都属于微体系结构层面的优化。
关键点是:程序员看到的抽象仍然像“指令按顺序执行”,但硬件内部为了快,已经做了大量并行工作。
9.3 SIMD:一条指令处理多份数据
SIMD 是 Single Instruction, Multiple Data。
意思是:一条指令同时对多个数据做同类操作。
比如普通加法:
a0 + b0 -> c0SIMD 可以类似:
[a0, a1, a2, a3] + [b0, b1, b2, b3] -> [c0, c1, c2, c3]这对图像、音频、视频、矩阵计算非常重要。
一个概念性例子:
typedef float v4sf __attribute__((vector_size(16)));
int main(void) {
v4sf a = {1.0, 2.0, 3.0, 4.0};
v4sf b = {10.0, 20.0, 30.0, 40.0};
v4sf c = a + b;
return (int)c[0];
}这使用 GCC 的向量扩展,让编译器有机会生成 SIMD 指令。
10. 抽象:计算机系统最伟大的工程思想
第 1 章最后真正想强调的是抽象。
计算机系统到处都是抽象:
应用程序看到:文件
实际下面是:磁盘、终端、网卡、驱动、缓冲区
应用程序看到:进程
实际下面是:CPU 时间片、上下文切换、页表、内核调度
程序看到:虚拟内存
实际下面是:物理内存、磁盘交换、地址翻译、权限检查
机器代码看到:顺序执行的指令
实际下面是:流水线、乱序执行、缓存、预测、并行执行抽象不是为了让你永远不懂底层。抽象是为了让你在大多数时候不用关心底层,但在性能、安全、可靠性出问题时,你能钻下去。
这也是 CSAPP 最值得学的地方。
它不是教你“记住 CPU 有哪些部件”,而是训练一种系统感:
当代码运行时,你能同时看到:
- 源代码层:我写了什么逻辑。
- 编译层:它会变成什么机器行为。
- 内存层:数据在哪里,如何移动。
- 操作系统层:进程、虚拟内存、文件描述符如何参与。
- 硬件层:缓存、寄存器、总线、I/O 如何影响性能。
11. 用一张图串起来:hello 的完整旅程
最后我们把 hello.c 的一生串起来:
你写 hello.c
↓
字符被保存成字节
↓
预处理器展开 #include 和宏
↓
编译器生成汇编
↓
汇编器生成目标文件
↓
链接器合并目标文件和库
↓
得到可执行文件 hello
↓
shell 读取 ./hello 命令
↓
shell 通过系统调用请求内核运行程序
↓
内核创建进程和虚拟地址空间
↓
可执行文件代码和数据被加载或映射到内存
↓
CPU 根据 PC 取指、译码、执行、更新 PC
↓
程序调用库函数输出字符串
↓
库函数触发 write 系统调用
↓
内核把字节写到终端设备
↓
屏幕显示 hello, world如果你能把这条链路讲清楚,CSAPP 第 1 章就不再是“概览”,而是一张地图。
后面的章节只是沿着这张地图,把每个区域挖深:
- 第 2 章:位如何表示整数和浮点数。
- 第 3 章:C 程序如何变成机器级代码。
- 第 5、6 章:性能和缓存为什么重要。
- 第 7 章:链接到底如何工作。
- 第 8 章:异常、进程、信号如何改变控制流。
- 第 9 章:虚拟内存如何支撑现代程序。
- 第 10、11 章:I/O 和网络编程。
- 第 12 章:并发编程。
12. 给读者的练习清单
如果你想真的掌握这一章,不要只读。动手做下面这些实验:
实验 1:观察编译四阶段
gcc -E hello.c -o hello.i
gcc -S hello.c -o hello.s
gcc -c hello.c -o hello.o
gcc hello.o -o hello然后分别观察:
less hello.i
less hello.s
xxd hello.o | head
file hello实验 2:观察符号和链接
nm hello.o
nm hello重点看 main、printf 或 puts 相关符号。
实验 3:观察系统调用
Linux 上可以用:
strace ./hello你会看到程序启动、加载库、写标准输出、退出等系统调用。
实验 4:观察虚拟地址
运行前面的地址打印程序,多运行几次,观察代码区、全局区、堆、栈地址的变化。
实验 5:测试缓存局部性
运行矩阵按行/按列访问实验,调大或调小 N,观察性能差异。
总结
CSAPP 第 1 章真正想告诉我们的,不是“计算机由硬件和软件组成”这么简单。
它想建立的是一种系统级直觉:
程序不是飘在云上的逻辑。程序是字节,是指令,是内存布局,是进程,是系统调用,是缓存命中或不命中,是数据在层次结构中的移动。
一个成熟程序员和普通程序员的差距,很多时候就在这里:
普通程序员看到:
printf("hello, world\n");系统程序员看到:
字符编码、编译链路、链接、进程创建、虚拟地址空间、指令执行、缓存层次、系统调用、I/O 抽象。同一句 hello, world,背后是一整台机器的协作。
这就是 CSAPP 第 1 章的美感:它用最小的程序,打开了最大的系统。