
工业化
大型语言模型正在快速工业化。
- 据称 GPT-4 拥有 1.8 万亿参数,训练成本约 1 亿美元。[article]
- xAI 为训练 Grok 建立了 20 万块 H100 GPU 的集群。[article]
- OpenAI、NVIDIA、Oracle 联合投资 5000 亿美元(四年内)建设 Stargate 项目。[article]
- 前沿模型的具体构建细节没有公开。
More is different
更多参数,表现就会不同
- 最前沿的大型模型目前我们难以企及,而构建参数量小于 10 亿的语言模型,可能并不能代表大型语言模型的真实特性。
- 例子 1(图 1):随着模型规模扩大,计算资源(FLOPs)在注意力机制(Attention)和前馈网络(MLP)之间的分配比例会显著变化。例如,OPT 模型从 7.6 亿参数到 1750 亿参数,Attention 占比逐渐下降,而 MLP 占比显著上升。[X]
- 例子 2(图 2,Wei 等 2022):某些能力会在模型规模达到一定量级后“涌现”(emergent behavior),即在小模型中几乎不存在,但在大模型中突然显著提升,比如算术推理、单词重组、多任务自然语言理解等任务的准确率在大规模训练 FLOPs 下陡然上升。[Wei+ 2022]
这说明:小模型的实验结果未必能直接推广到大模型,因为规模不仅影响性能,还会带来新的能力与计算结构分配的变化。
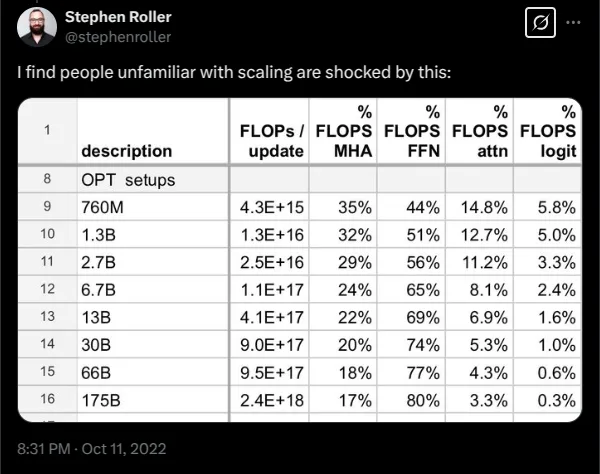
图1
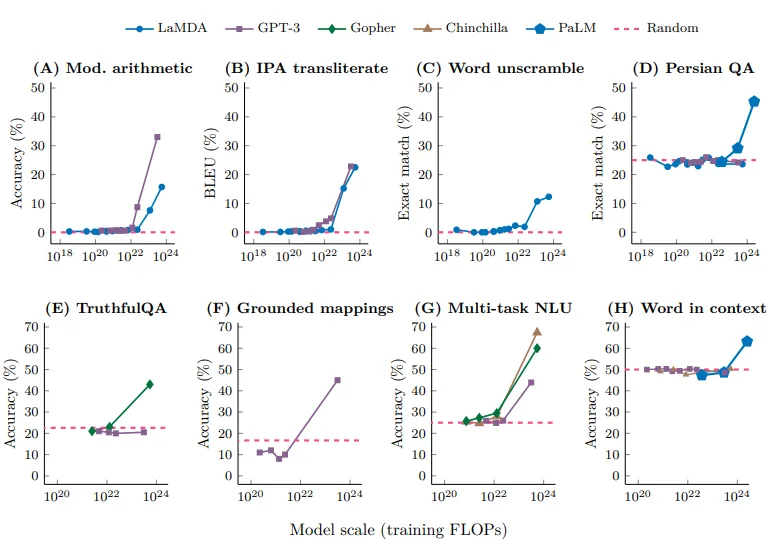
图2
What can we learn in this class that transfers
to frontier models?
在这门课中,我们能学到三类可迁移到前沿模型的知识:
- 机制(Mechanics):了解技术原理,如 Transformer 的工作方式、模型并行如何利用 GPU 等。
- 思维方式(Mindset):充分利用硬件、认真对待规模效应(如缩放定律)。
- 直觉(Intuitions):哪些数据和建模决策能带来更高的准确率。
课程可以完整教授机制和思维方式(可直接迁移),但直觉只能部分传授,因为它并不总是能跨规模迁移。很多设计决策目前还无法通过理论完全证明,只能依赖实验探索——例如 Noam Shazeer 在 2020 年提出的 SwiGLU 激活函数就是这样得出的。
直觉?
- 一些设计决策目前无法完全用理论解释,只能依靠实验探索。
- 例子:Noam Shazeer 在 2020 年提出 SwiGLU 激活函数。
The bitter lesson
- “痛苦的教训”正确理解:关键是可扩展的算法,而不是单纯规模或算法本身。
- 准确率公式:准确率 = 效率 × 资源;在大规模下效率更重要,因为资源浪费不起。
- 研究(Hernandez+ 2020)显示:2012-2019 年 ImageNet 算法效率提升了 44 倍。
- 思路:在固定计算与数据预算下,构建最优模型,本质是最大化效率。
当前状况
- 前神经网络时代(2010 年前)
- 香农 1950:用语言模型测量英语熵。[shannon 1950]
- n-gram 语言模型应用于机器翻译、语音识别(Brants+ 2007)。[Brants + 2007]
- 神经网络要素(2010 年代)
- 首个神经语言模型(Bengio+ 2003)。[Bengio+ 2003]
- 序列到序列建模(Sutskever+ 2014)。[Sutskever+ 2014]
- Adam 优化器(Kingma+ 2014)。[Kingma+ 2014]
- 注意力机制(Bahdanau+ 2014)。[Bahdanau+ 2014]
- Transformer 架构(Vaswani+ 2017)。[Vaswani+ 2017]
- 专家混合模型(Shazeer+ 2017)。[Shazeer+ 2017]
- 模型并行(Huang+ 2018; Rajbhandari+ 2019; Shoeybi+ 2019)。**[Huang+ 2018][Rajbhandari+ 2019][Shoeybi+ 2019]**
- 早期基础模型(2010 年代末)
- ELMo:LSTM 预训练 + 微调提升任务表现(Peters+ 2018)。[Peters+ 2018]
- BERT:Transformer 预训练 + 微调(Devlin+ 2018)。[Devlin+ 2018]
- T5(11B):统一为文本到文本(Raffel+ 2019)。[Raffel+ 2019]
- 扩展规模与封闭化趋势
- GPT-2(1.5B):流畅文本,零样本萌芽,分阶段发布(Radford+ 2019)。[Radford+ 2019]
- Scaling laws:提供规模可预测性(Kaplan+ 2020)。[Kaplan+ 2020]
- GPT-3(175B):上下文学习,封闭(Brown+ 2020)。[Brown+ 2020]
- PaLM(540B):超大规模,训练不足(Chowdhery+ 2022)。[Chowdhery+ 2022]
- Chinchilla(70B):计算最优缩放(Hoffmann+ 2022)。[Hoffmann+ 2022]
- 开放模型
- EleutherAI:The Pile 数据集与 GPT-J 模型(Gao+ 2020; Wang+ 2021)。**[Gao+ 2020][Wang+ 2021]**
- Meta:OPT(175B)复现 GPT-3,硬件问题多(Zhang+ 2022)。[Zhang+ 2022]
- BLOOM:专注数据来源(Workshop+ 2022)。[Workshop+ 2022]](https://arxiv.org/abs/2211.05100)
- Llama 系列(Touvron+ 2023, 2024)。**[Touvron+ 2023][Touvron+ 2023][Grattafiori+ 2024]**
- 阿里巴巴 Qwen 系列(2024)。[Qwen+ 2024]
- DeepSeek 系列(2024)。**[DeepSeek-AI+ 2024][DeepSeek-AI+ 2024][DeepSeek-AI+ 2024]**
- AI2 的 OLMo 2(2024)。**[Groeneveld+ 2024][OLMo+ 2024]**
- 开放程度层次
- 封闭模型:仅 API 访问(如 GPT-4o)。[OpenAI+ 2023]
- 开放权重模型:权重可用,架构细节公开,部分训练细节,无数据细节(如 DeepSeek)。[DeepSeek-AI+ 2024]
- 开源模型:权重与数据可用,论文细节较全(如 OLMo)。[Groeneveld+ 2024]
效率驱动设计决策
- 当前受计算资源限制,设计决策应最大化硬件利用效率。
- 数据处理:避免在低质量或无关数据上浪费计算。
- 分词:直接使用原始字节虽然优雅,但计算效率低。
- 模型架构:多项改动旨在减少内存或 FLOPs,例如共享 KV 缓存、滑动窗口注意力。
- 训练:单轮训练即可。
- 缩放法则:小模型用较少计算进行超参数调优。
- 对齐(Alignment):针对特定应用微调时,可使用较小基模型。
- 未来趋势:将受数据限制。
Tokenizer
分词(Tokenization)
- 分词器负责将字符串转换为整数序列(即标记或tokens)。
- 其核心思想是将字符串分解成常用的片段。
- 本次课程使用**字节对编码(Byte-Pair Encoding, BPE)**分词器。[Sennrich+ 2015]
无分词器方法(Tokenizer-free approaches)**[Xue+ 2021][Yu+ 2023][Pagnoni+ 2024][Deiseroth+ 2024]**
- 这些方法直接使用字节作为处理单元。
- 前景光明,但目前尚未扩展到前沿模型规模。
架构(Architecture)
模型架构
起点:原始Transformer模型。
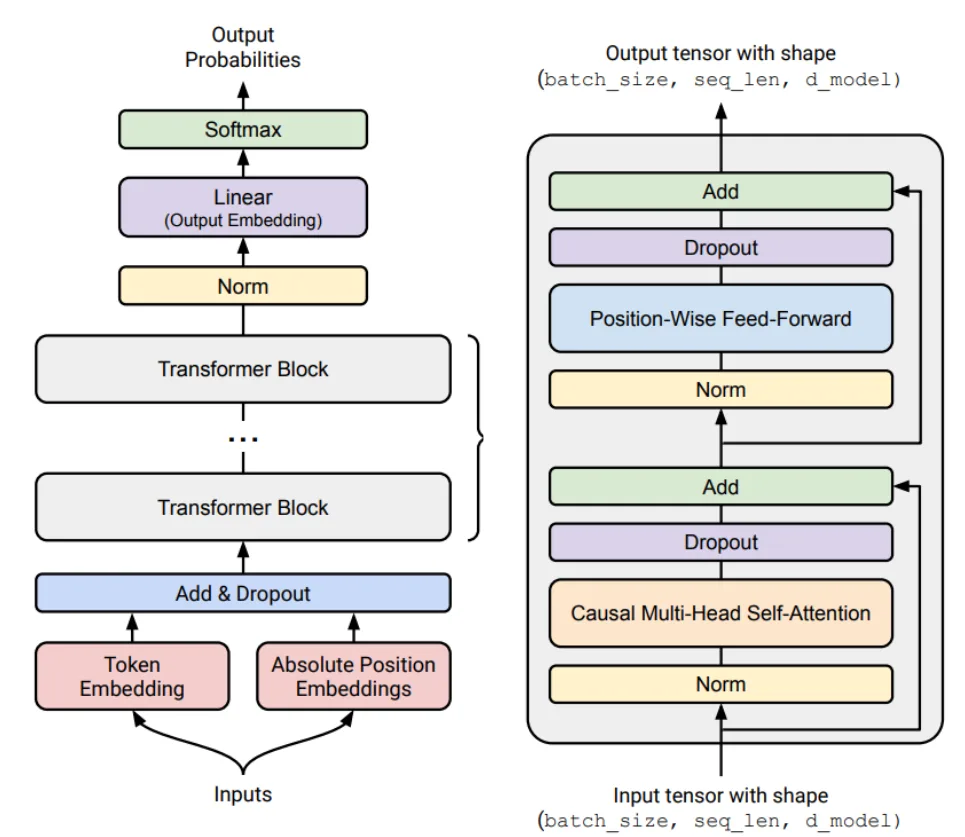
主要变体:
- 激活函数:从ReLU到SwiGLU。[Shazeer 2020]
- 位置编码:从正弦(sinusoidal)到RoPE。[Su+ 2021]
- 归一化:从LayerNorm到RMSNorm。**[Ba+ 2016][Zhang+ 2019]**
- 归一化位置:前归一化(pre-norm)与后归一化(post-norm)。[Xiong+ 2020]
- MLP(多层感知机):从密集连接到专家混合(Mixture of Experts)。[Shazeer+ 2017]
- 注意力机制:从全注意力到滑动窗口、线性注意力。**[Jiang+ 2023][Katharopoulos+ 2020]**
- 低维注意力:包括组查询注意力(GQA)和多头潜在注意力(MLA)。**[Ainslie+ 2023][DeepSeek-AI+ 2024]**
- 状态空间模型:如Hyena。[Poli+ 2023]
训练(Training)
- 优化器:如AdamW、Muon、SOAP,用于更新模型参数。**[Kingma+ 2014][Loshchilov+ 2017][Keller 2024][Vyas+ 2024]**
- 学习率调度:如余弦(cosine)、WSD,用于动态调整学习率。**[Loshchilov+ 2016][Hu+ 2024]**
- 批量大小:例如关键批量大小(critical batch size)。
- 正则化:如Dropout和权重衰减(weight decay),用于防止过拟合。
- 超参数:如注意力头数、隐藏层维度,通常通过网格搜索(grid search)等方法进行调整。
Kernels
GPU (A100)

类比
仓库(warehouse) 相当于DRAM(动态随机存取存储器),而工厂(factory) 相当于SRAM(静态随机存取存储器)。
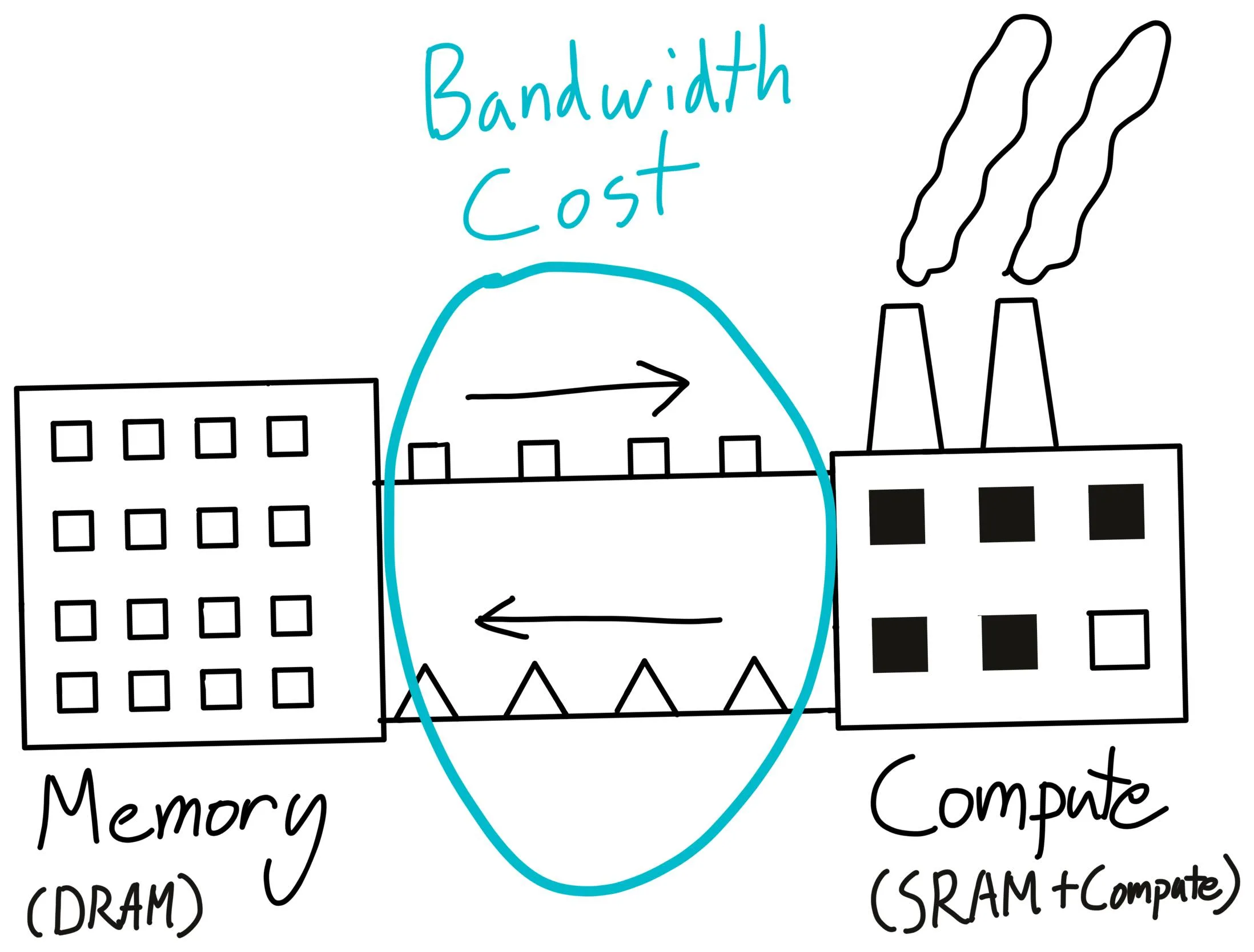
技巧
- 组织计算:通过最小化数据移动来最大化GPU的利用率。
- 编写内核(kernels):使用CUDA、Triton、CUTLASS或ThunderKittens等工具来优化计算。
Parallelism
核心原则:即使在多GPU之间,数据移动也更慢,因此最小化数据移动的原则依然成立。
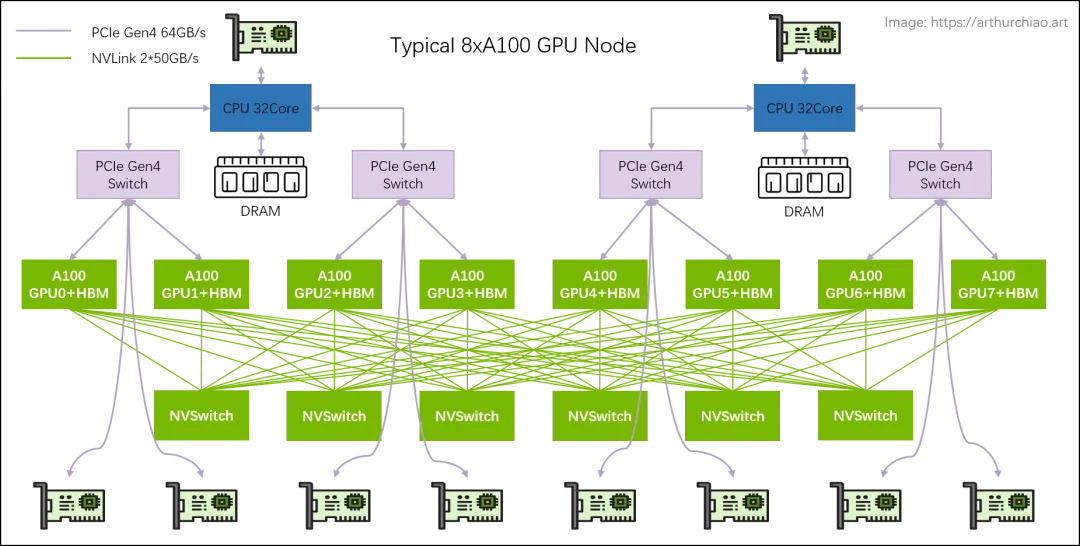
主要方法:
- 集体操作:使用
gather、reduce、all-reduce等集体通信操作。 - 分片:将参数、激活、梯度和优化器状态等**分片(Shard)**到不同的GPU上。
- 计算拆分:根据不同的并行策略(如数据并行、张量并行、流水线并行、序列并行)来拆分计算任务。
Inference
目标:根据给定的提示(prompt)生成标记(tokens),这是实际使用模型的关键环节。
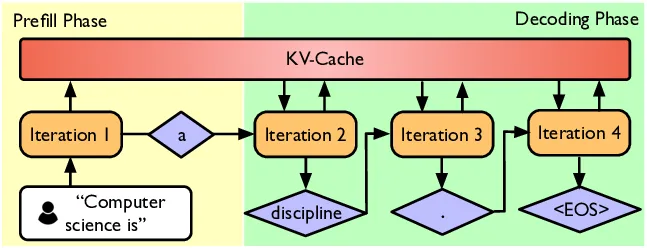
应用场景:除了生成内容,推理还用于强化学习、测试计算和模型评估。
全局成本:推理计算(每次使用)的总量超过训练计算(一次性成本)。
两个阶段:
- 预填充(Prefill):处理输入的提示文本,可以一次性处理所有标记,此阶段受计算限制。
- 解码(Decode):一次生成一个标记,此阶段受内存限制。
加速解码的方法
- 使用更轻量的模型:通过模型剪枝、量化或蒸馏等技术来降低模型复杂度。
- 推测解码(Speculative decoding):使用一个较小、速度更快的“草稿”模型生成多个标记,然后让完整模型并行地对这些标记进行评分,从而实现精确解码。
- 系统优化:利用**KV缓存(KV caching)和批处理(batching)**等技术来提高效率。
Scaling laws
主要用于在大规模训练前,从小规模实验中预测最优的超参数和损失。
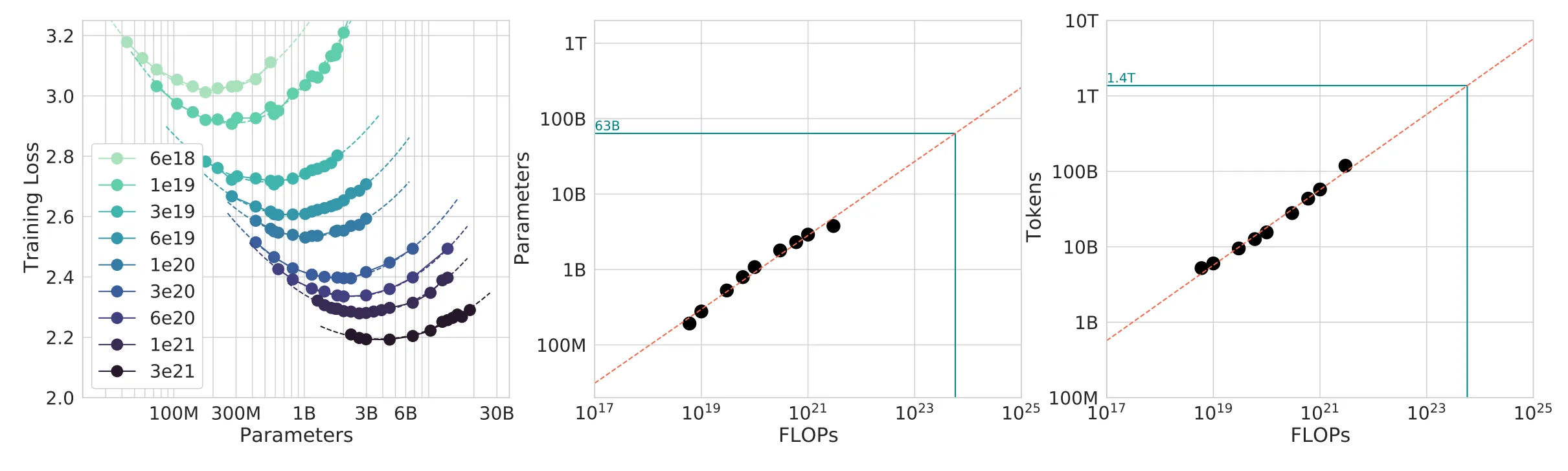
- 目标:通过小规模实验,预测大规模训练时的超参数和损失。
- 核心问题:在给定的计算预算(FLOPs)下,是选择更大的模型(增加参数量N),还是用**更多的数据(增加标记D)**进行训练?
- 计算最优缩放定律:
- 结论:。这意味着一个参数量为1.4亿的模型,应该在约280亿个标记上进行训练,以达到计算最优。
- 局限性:此定律没有考虑推理成本。
Data
- 核心问题:我们希望模型具备哪些能力?
- 能力来源:模型的具体能力(如多语言支持、代码理解、数学推理等)取决于所使用的训练数据。
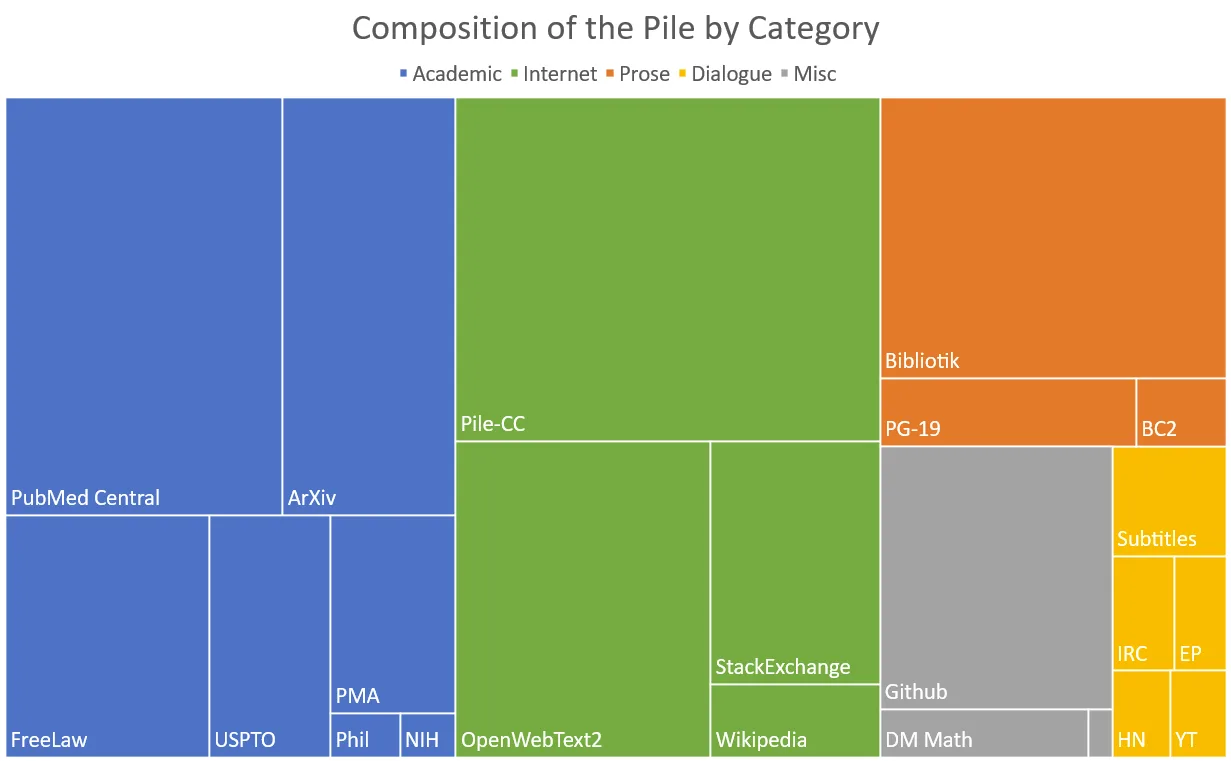
Evaluation
- 困惑度(Perplexity):这是语言模型的教科书式评估方法。
- 标准化测试:使用一系列标准化的测试集,如MMLU、HellaSwag、GSM8K,来评估模型的知识和能力。
- 指令遵循:评估模型遵循指令的能力,常用工具包括AlpacaEval、IFEval、WildBench。
- 扩展测试时的计算:通过**思维链(chain-of-thought)和集成(ensembling)**等方法,在推理时增加计算量以提高性能。
- 以大模型作为评委(LM-as-a-judge):利用一个强大的语言模型作为裁判,来评估生成任务的质量。
- 完整系统评估:评估一个包含**RAG(检索增强生成)和代理(agents)**等组件的完整系统。
Alignment
- 指令遵循:让语言模型能够按照用户的指令进行操作。
- 风格调整:调整模型的输出风格,包括格式、长度、语气等。
- 安全性:确保模型能够安全地运作,例如拒绝回答有害的问题。
对齐的两个阶段
- 有监督微调(Supervised finetuning):通过使用人工标注的数据对模型进行微调。
- 从反馈中学习(Learning from feedback):通常指通过人类反馈强化学习(RLHF)等方法,进一步优化模型行为。
Supervised finetuning (SFT)
sft_data: list[ChatExample] = [
ChatExample(
turns=[
Turn(role="system", content="You are a helpful assistant."),
Turn(role="user", content="What is 1 + 1?"),
Turn(role="assistant", content="The answer is 2."),
],
),
]- 核心思想:利用指令数据对基础模型进行微调。
- 指令数据:由**(提示, 回应)**对组成,通常包含人工标注的示例,例如:“你是乐于助人的助手。”、“1+1等于几?”、“答案是2。”
- 原理:基础模型已经具备所需技能,只需通过少量示例激发这些能力。
- 方法:采用有监督学习,通过微调模型来最大化在给定提示下生成正确回应的概率。
Preference data
preference_data: list[PreferenceExample] = [
PreferenceExample(
history=[
Turn(role="system", content="You are a helpful assistant."),
Turn(role="user", content="What is the best way to train a language model?"),
],
response_a="You should use a large dataset and train for a long time.",
response_b="You should use a small dataset and train for a short time.",
chosen="a",
)
]数据生成方式:
- 对于一个给定的提示(prompt),模型会生成多个不同的回应,例如
[A, B]。 - 用户随后提供偏好,例如选择
A优于B或B优于A。
数据示例:一个偏好数据示例可能包含:
- 对话历史:如“你是一个乐于助人的助手。”和“训练语言模型的最佳方法是什么?”
- 两个备选回应:例如
response_a和response_b。 - 用户选择:用户选择
a作为更优的回应。
Algorithm
- 近端策略优化(Proximal Policy Optimization, PPO):一种来自强化学习领域的算法,用于优化模型策略。[Schulman+ 2017]
- 直接策略优化(Direct Policy Optimization, DPO):一种处理偏好数据的简化算法。[Rafailov+ 2023]
- 群组相对偏好优化(Group Relative Preference Optimization, GRPO):一种移除价值函数的对齐算法。[Shao+ 2024]
Tokenization
GPT-2 Tokenizer Regex
GPT2_TOKENIZER_REGEX = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
Tokenization 总览
-
Tokenizer 将 字符串 ↔ token(索引)
-
常见方法:
-
Character-based
-
Byte-based
-
Word-based
这些方法通常效果不理想。
-
-
BPE(Byte Pair Encoding) 是基于语料统计的有效启发式方法。
-
Tokenization 是必要的步骤,将来可能直接从 bytes 处理。
BPETokenizer 参数
from dataclasses import dataclass
@dataclass(frozen=True)
class BPETokenizerParams:
"""BPETokenizer 所需的全部参数"""
vocab: dict[int, bytes] # index -> bytes
merges: dict[tuple[int, int], int] # index1, index2 -> new_index
各类 Tokenizer 实现
Character Tokenizer
class CharacterTokenizer(Tokenizer):
"""将字符串表示为 Unicode code points 序列"""
def encode(self, string: str) -> list[int]:
return list(map(ord, string))
def decode(self, indices: list[int]) -> str:
return "".join(map(chr, indices))
Byte Tokenizer
class ByteTokenizer(Tokenizer):
"""将字符串表示为字节序列"""
def encode(self, string: str) -> list[int]:
string_bytes = string.encode("utf-8")
indices = list(map(int, string_bytes))
return indices
def decode(self, indices: list[int]) -> str:
string_bytes = bytes(indices)
string = string_bytes.decode("utf-8")
return string
BPE 合并函数
def merge(indices: list[int], pair: tuple[int, int], new_index: int) -> list[int]:
"""返回合并后的 indices,将所有 pair 替换为 new_index"""
new_indices = []
i = 0
while i < len(indices):
if i + 1 < len(indices) and indices[i] == pair[0] and indices[i + 1] == pair[1]:
new_indices.append(new_index)
i += 2
else:
new_indices.append(indices[i])
i += 1
return new_indices
BPE Tokenizer
class BPETokenizer(Tokenizer):
"""基于 merges 和 vocab 的 BPE tokenizer"""
def __init__(self, params: BPETokenizerParams):
self.params = params
def encode(self, string: str) -> list[int]:
indices = list(map(int, string.encode("utf-8")))
# 注意:实现非常慢
for pair, new_index in self.params.merges.items():
indices = merge(indices, pair, new_index)
return indices
def decode(self, indices: list[int]) -> str:
bytes_list = list(map(self.params.vocab.get, indices))
string = b"".join(bytes_list).decode("utf-8")
return string
压缩率计算
def get_compression_ratio(string: str, indices: list[int]) -> float:
"""计算 tokenization 后的压缩率"""
num_bytes = len(bytes(string, encoding="utf-8"))
num_tokens = len(indices)
return num_bytes / num_tokens
获取 GPT-2 Tokenizer
def get_gpt2_tokenizer():
# 使用 tiktoken
# 对应 GPT-3.5-turbo 或 GPT-4 可使用 cl100k_base
return tiktoken.get_encoding("gpt2")
Tokenization 示例
原始文本通常表示为 Unicode 字符串
语言模型对 token 序列(整数索引)建立概率分布
Tokenizer 负责将字符串编码为 token,并能解码回字符串
Vocabulary size = 可用 token 数量
示例代码
string = "Hello, 🌍! 你好!"
tokenizer = get_gpt2_tokenizer()
# 编码 & 解码检查
indices = tokenizer.encode(string)
reconstructed_string = tokenizer.decode(indices)
assert string == reconstructed_string
# 压缩率
compression_ratio = get_compression_ratio(string, indices)
Observations
- 单词及其前置空格是同一个 token(例如
" world") - 相同单词在不同位置可能表示不同 token(例如
"hello hello") - 数字被分割为若干 token
Tokenization 方法详解
Character-based Tokenizer
- 将字符串表示为 Unicode 字符序列
- 每个字符可通过
ord()转换为整数 code point - 可通过
chr()还原为字符
assert ord("a") == 97
assert ord("🌍") == 127757
assert chr(97) == "a"
assert chr(127757) == "🌍"
示例
tokenizer = CharacterTokenizer()
string = "Hello, 🌍! 你好!"
indices = tokenizer.encode(string)
reconstructed_string = tokenizer.decode(indices)
assert string == reconstructed_string
特点与问题
- Unicode 大约有 150K 个字符 → 词表非常大
- 很多字符出现频率低(如 🌍) → 词表利用率低
- 压缩率计算:
compression_ratio = get_compression_ratio(string, indices)
Byte-based Tokenizer
- 将字符串表示为 字节序列(整数 0~255)
- 使用 UTF-8 编码
# 单字节字符
assert bytes("a", encoding="utf-8") == b"a"
# 多字节字符
assert bytes("🌍", encoding="utf-8") == b"\xf0\x9f\x8c\x8d"
示例
tokenizer = ByteTokenizer()
string = "Hello, 🌍! 你好!"
indices = tokenizer.encode(string)
reconstructed_string = tokenizer.decode(indices)
assert string == reconstructed_string
特点
- 词表固定且较小:256 个字节
- 压缩率较低(
compression_ratio == 1),序列过长 → Transformer 注意力开销大
vocabulary_size = 256
compression_ratio = get_compression_ratio(string, indices)
Word-based Tokenizer
- 传统 NLP 方法,将字符串按 单词或符号 切分
import regex
string = "I'll say supercalifragilisticexpialidocious!"
segments = regex.findall(r"\w+|.", string) # 保留单词和标点
- 使用 GPT-2 Tokenizer 正则表达式可改进:
pattern = GPT2_TOKENIZER_REGEX
segments = regex.findall(pattern, string)
构建 Tokenizer
- 将每个 segment 映射为整数
- 构建映射表:segment → token
问题
- 词表可能非常大
- 很多单词出现频率低 → 模型学习有限
- 无法保证固定词表大小
- 新词出现 → 使用特殊 UNK token → 影响困惑度计算
vocabulary_size = "Number of distinct segments in the training data"
compression_ratio = get_compression_ratio(string, segments)
BPE Tokenizer (Byte Pair Encoding)
- BPE 最初用于数据压缩(Philip Gage 1994)
- NLP 中用于神经机器翻译(Sennrich+ 2015)
- GPT-2 使用 BPE 进行分词(Radford+ 2019)
基本思想
- 常用字符序列 → 一个 token
- 少见序列 → 多个 token
- 初始分词:每个字节为一个 token
- 迭代合并最常见的相邻 token 对
训练 BPE Tokenizer
def train_bpe(string: str, num_merges: int) -> BPETokenizerParams:
indices = list(map(int, string.encode("utf-8")))
merges: dict[tuple[int, int], int] = {}
vocab: dict[int, bytes] = {x: bytes([x]) for x in range(256)}
for i in range(num_merges):
# 统计相邻 token 对出现次数
counts = defaultdict(int)
for index1, index2 in zip(indices, indices[1:]):
counts[(index1, index2)] += 1
# 找出最常见的 pair
pair = max(counts, key=counts.get)
index1, index2 = pair
# 合并 pair
new_index = 256 + i
merges[pair] = new_index
vocab[new_index] = vocab[index1] + vocab[index2]
indices = merge(indices, pair, new_index)
return BPETokenizerParams(vocab=vocab, merges=merges)
使用 BPE Tokenizer
params = train_bpe("the cat in the hat", num_merges=3)
tokenizer = BPETokenizer(params)
string = "the quick brown fox"
indices = tokenizer.encode(string)
reconstructed_string = tokenizer.decode(indices)
assert string == reconstructed_string