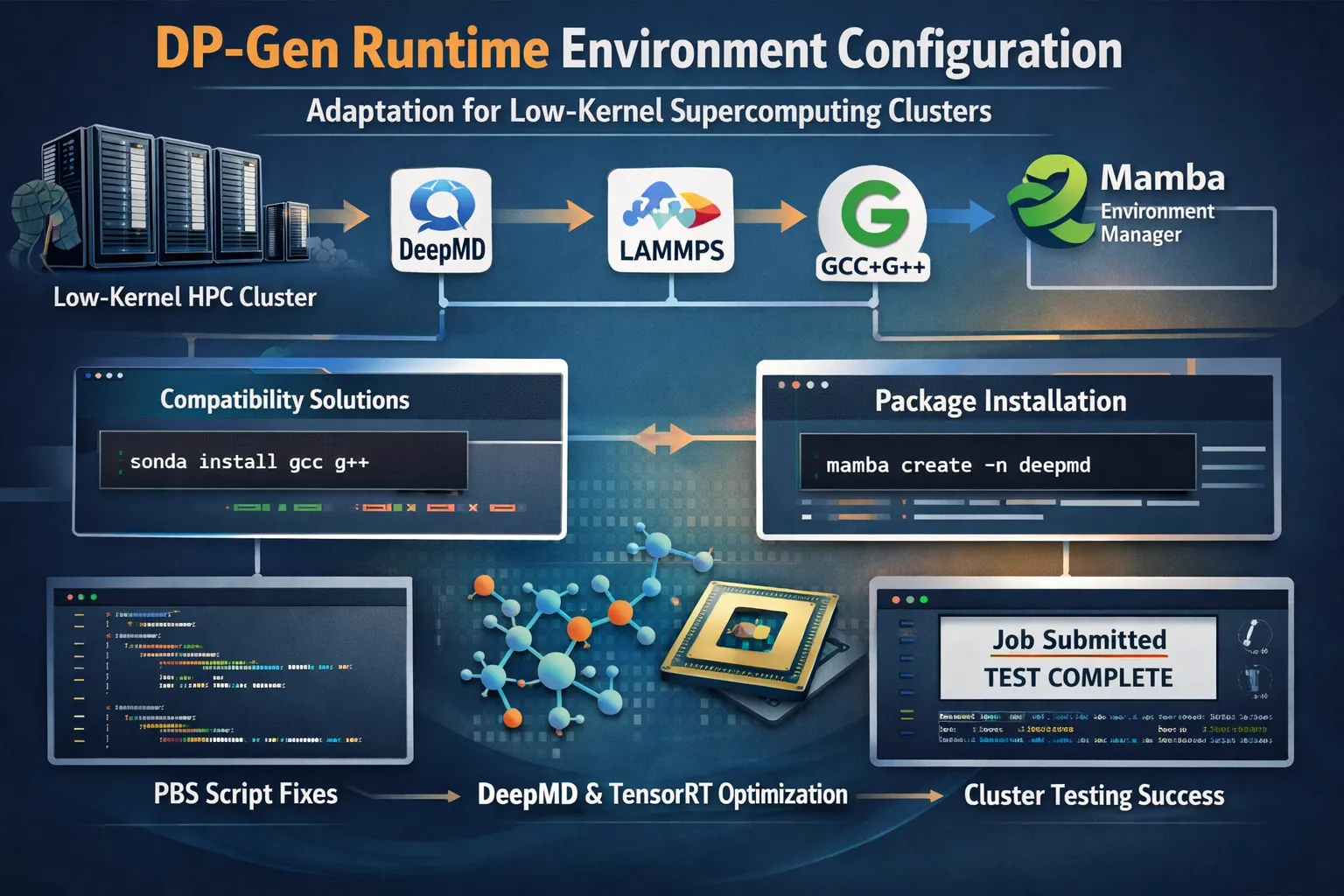
环境创建
Deepmd-kit与lammps兼容问题,在尝试多个版本后,找到最佳解决方案
-
安装兼容的
GCC和G++(推荐conda-forge,base环境)bashmamba install -c conda-forge gcc_linux-64 gxx_linux-64 mamba install -c conda-forge compilers -
安装
mambabashconda install mamba -n base -c conda-forgemamba管理conda环境,避免多个环境造成资源消耗。
修改**
~/.bashrc** ,mamba第一次执行activate有相关提示,将MAMBA_EXE和MAMBA_ROOT_PREFIX修改到conda目录bash# >>> mamba initialize >>> # !! Contents within this block are managed by 'mamba shell init' !! export MAMBA_EXE='/cache/jxgan2024/miniconda/bin/mamba'; export MAMBA_ROOT_PREFIX='/cache/jxgan2024/miniconda'; __mamba_setup="$("$MAMBA_EXE" shell hook --shell bash --root-prefix "$MAMBA_ROOT_PREFIX" 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__mamba_setup" else alias mamba="$MAMBA_EXE" # Fallback on help from mamba activate fi unset __mamba_setup # <<< mamba initialize <<< -
安装
deepmd,lammps通过
mamba有效解决环境冲突问题,如遇到环境冲突mamba将终止安装。安装完成,测试lmp -h查看pair-style若没有deepmd,不一定是安装失败,可直接提交任务测试bashmamba create -n deepmd deepmd-kit=*=*gpu libdeepmd=*=*gpu lammps cudatoolkit horovod -c conda-forge -
安装
dpgenbashpip install dpgen -
安装
dpdatabashpip install dpdata -
解决
dpgen与课题组集群pbs命令冲突问题-
在DPGEN文件路径:
your-conda-home/envs/deepmd/lib/python3.9/site-packages/dpgen/auto_test/lib/vasp.py中修改K点pythondef _make_vasp_kp_gamma(kpoints): ret = "" ret += "Automatic mesh\n" ret += "0\n" ret += "Gamma\n" ret += "%d %d %d\n" % (kpoints[0], kpoints[1], kpoints[2]) # noqa: UP031 ret += "0 0 0\n" return ret def _make_vasp_kp_mp(kpoints): ret = "" ret += "K-Points\n" ret += " 0\n" ret += "Monkhorst Pack\n" ret += "%d %d %d\n" % (kpoints[0], kpoints[1], kpoints[2]) # noqa: UP031 ret += " 0 0 0\n" return ret -
pbs命令纠正your-conda-home/envs/deepmd/lib/python3.9/site-packages/dpdispatcher/machines/pbs.pyqstat命令参数错误bashcommand = "qstat -x " + job_id修改为(记得最后一个空格):
bashcommand = "qstat " + job_id -
pbs纠正your-conda-home/envs/deepmd/lib/python3.9/site-packages/dpdispatcher/machines/pbs.pypbs资源请求参数错误pythonpbs_script_header_dict["select_node_line"] = ( f"#PBS -l select={resources.number_node}:ncpus={resources.cpu_per_node}" )修改为:
pythonpbs_script_header_dict["select_node_line"] = ( f"#PBS -l nodes={resources.number_node}:ppn={resources.cpu_per_node}" ) -
lammps脚本输入位置修改
/cache/jxgan2024/miniconda/envs/deepmd3/lib/python3.10/site-packages/dpgen/generator/lib/lammps.py
-
-
TensorRT安装(用于性能优化)
bashconda install -c nvidia tensorrt
数据集构建
AIMD计算
低精度
Global Parameters
ISTART = 0 (Read existing wavefunction, if there)
ISPIN = 1 (Non-Spin polarised DFT)
# ICHARG = 11 (Non-self-consistent: GGA/LDA band structures)
LREAL = A (Projection operators: automatic)
ENCUT = 400 (Cut-off energy for plane wave basis set, in eV)
LWAVE = .FALSE. (Write WAVECAR or not)
LCHARG = .FALSE. (Write CHGCAR or not)
ADDGRID= .FALSE. (Increase grid, helps GGA convergence)
PREC = N (Accurate strictly avoids any aliasing or wrap around errors)
ISYM = 0
ALGO = Fast
NWRITE = 2
# Tempareture
TEBEG = 700
TEEND = 200
Electronic Relaxation
ISMEAR = 0 (Gaussian smearing, metals:1)
SIGMA = 0.05 (Smearing value in eV, metals:0.2)
NELM = 60 (Max electronic SCF steps)
NELMIN = 4 (Min electronic SCF steps)
EDIFF = 1E-04 (SCF energy convergence, in eV)
Ionic Relaxation
NSW = 5000 (Max ionic steps)
IBRION = 0 (Algorithm: 0-MD, 1-Quasi-New, 2-CG)
ISIF = 3 (Stress/relaxation: 2-Ions, 3-Shape/Ions/V, 4-Shape/Ions)
POTIM = 2
MDALGO = 3
# 解决VASP的old and new charge differ
LSCALAPACK = .FALSE.
# core
NPAR = 4
# 范德华修正
IVDW = 11 (Grimme-D3方法的vdW修正)
# VDW_S8 = 1.0单步高精度
Global Parameters
ISTART = 0 (Read existing wavefunction, if there)
ISPIN = 1 (Non-Spin polarised DFT)
# ICHARG = 11 (Non-self-consistent: GGA/LDA band structures)
LREAL = A (Projection operators: automatic)
ENCUT = 400 (Cut-off energy for plane wave basis set, in eV)
LWAVE = .FALSE. (Write WAVECAR or not)
LCHARG = .FALSE. (Write CHGCAR or not)
ADDGRID= .FALSE. (Increase grid, helps GGA convergence)
PREC = N (Accurate strictly avoids any aliasing or wrap around errors)
ISYM = 2
ALGO = N
NWRITE = 2
Electronic Relaxation
ISMEAR = 0 (Gaussian smearing, metals:1)
SIGMA = 0.05 (Smearing value in eV, metals:0.2)
NELM = 60 (Max electronic SCF steps)
NELMIN = 4 (Min electronic SCF steps)
EDIFF = 1E-04 (SCF energy convergence, in eV)
Ionic Relaxation
NSW = 0 (Max ionic steps)
IBRION = 0 (Algorithm: 0-MD, 1-Quasi-New, 2-CG)
ISIF = 3 (Stress/relaxation: 2-Ions, 3-Shape/Ions/V, 4-Shape/Ions)
POTIM = 2
MDALGO = 3
# 解决VASP的old and new charge differ
LSCALAPACK = .FALSE.
# core
NPAR = 4
# 范德华修正
IVDW = 11 (Grimme-D3方法的vdW修正)文件结构
.
├── Bi-pmn21-551-500
│ ├── POSCAR-0
│ ├── POSCAR-1
│ └── ...
├── Bi-pmn21-551-500-cal
│ ├── 0
│ │ ├──INCAR
│ │ ├──KPOINTS
│ │ ├──POSCAR
│ │ ├──POTCAR
│ │ ├──vasp-jobs
│ │ └── ...
│ ├── 1
│ │ ├──INCAR
│ │ ├──KPOINTS
│ │ ├──POSCAR
│ │ ├──POTCAR
│ │ ├──vasp-jobs
│ │ └── ...
├── Bi-pmna-551-500
│ └── ...
├── Bi-pmna-551-500-cal
│ └── ...
├── build_dataset.sh
├── export_data.py
├── INCAR
├── jobs-shell
├── KPOINTS
├── POTCAR
└── vasp-jobsbuild_dataset.h 单步高精度任务提交
#!/bin/bash
root_path=$(pwd)
for jj in Bi-pmna-551-500 ; do
dir=$jj'-cal'
echo $dir
mkdir -p $dir
nub=$(find "$jj" -type f | wc -l)
echo $nub
steps=0
for j in $(seq 0 $(($nub - 1))); do
mkdir -p $dir/$j
cd $dir/$j
ln -sf ../../INCAR INCAR
ln -sf ../../KPOINTS KPOINTS
ln -sf ../../POTCAR POTCAR
# ln -sf ../../jobs-fatcpuQ jobs-fatcpuQ
ln -sf ../../jobs-shell jobs-shell
# ln -sf ../../jobs-six_hours jobs-six_hours
ln -sf ../../vasp-jobs vasp-jobs
cp ../../$jj/POSCAR-$j POSCAR
sh jobs-shell
cd $root_path
# 正确增加计数器
steps=$((steps+1))
echo "当前完成步数: $steps"
done
echo "完成目录 $jj 的处理,总共执行了 $steps 步"
doneexport_data.py 转换为deepmd数据格式
import os
import dpdata
from numpy import *
import matplotlib.pyplot as plt
from tqdm import tqdm
from pathlib import Path
import sys
from caesar.logger.logger import setup_logger
logger = setup_logger(__name__)
def process_dataset(dataset_name: str, current_path: str) -> None:
"""处理单个数据集
Args:
dataset_name: 数据集名称
current_path: 当前工作目录
"""
try:
file_path = os.path.join(current_path, dataset_name)
if not os.path.exists(file_path):
logger.error(f"数据集路径不存在: {file_path}")
return
dir_list = [d for d in os.listdir(file_path) if d.isdigit()]
if not dir_list:
logger.warning(f"数据集 {dataset_name} 中没有找到数字命名的文件夹")
return
dir_list_sorted = sorted(dir_list, key=lambda x: int(x), reverse=False)
output_dir = Path(dataset_name[:-4] + '-train-data')
output_dir.mkdir(exist_ok=True)
logger.info(f"开始处理数据集: {dataset_name}")
for index in tqdm(dir_list_sorted,
desc=f"处理 {dataset_name}",
colour='#ffffcc'):
try:
index_file = os.path.join(file_path, index)
vasprun = os.path.join(index_file, 'vasprun.xml')
if not os.path.exists(vasprun):
logger.warning(f"文件不存在: {vasprun}")
continue
dsys = dpdata.LabeledSystem(vasprun)
output_path = output_dir / str(index)
dsys.to_deepmd_npy(str(output_path))
dsys.to_deepmd_raw(str(output_path))
logger.debug(f"成功处理文件夹: {index}")
except Exception as e:
logger.error(f"处理文件夹 {index} 时出错: {str(e)}")
continue
except Exception as e:
logger.error(f"处理数据集 {dataset_name} 时出错: {str(e)}")
def main():
"""主函数"""
try:
current_path = os.getcwd()
logger.info(f"当前工作目录: {current_path}")
dataset_path = ['Bi-pmn21-551-500-cal', 'Bi-pmna-551-500-cal']
for dataset in tqdm(dataset_path,
desc="总进度",
colour='#99cccc'):
process_dataset(dataset, current_path)
logger.info("所有数据集处理完成!")
except Exception as e:
logger.error(f"程序执行出错: {str(e)}")
sys.exit(1)
if __name__ == "__main__":
main()
训练势函数
文件目录结构
├── init
│ ├── Bi-pmn21-551-500-train-data
│ ├── Bi-pmna-551-500-train-data
│ ├── POSCAR-pmn21-551
│ └── POSCAR-pmna-551
├── run
│ ├── dpdispatcher.log (dpgen生成)
│ ├── dpgen.log (dpgen生成)
│ ├── dp-run
│ ├── INCAR_vasp
│ ├── iter.000000 (dpgen生成)
│ ├── machine.json
│ ├── param.json
│ ├── POTCAR
│ └── record.dpgen (dpgen生成)
└── work (dpgen生成)machine.json
{
"api_version": "1.0",
"deepmd_version": "2.2.10",
"train": [
{
"command": "dp",
"machine": {
"batch_type": "pbs",
"context_type": "local",
"machine_type": "shell",
"local_root": "./",
"remote_root": "../work/"
},
"resources": {
"number_node": 1,
"cpu_per_node": 4,
"_gpu_per_node": 1,
"queue_name": "gpuQ",
"group_size": 1,
"custom_flags": [
"#PBS -N dpgen",
"#PBS -l walltime=30:00:00:00",
"#PBS -W x=GRES:gpu@1",
"#PBS -S /bin/bash",
"source activate deepmd3",
"export OMP_NUM_THREADS=4",
"export TF_ENABLE_ONEDNN_OPTS=0"
]
}
}
],
"model_devi": [
{
"command": "mpirun -n 4 lmp",
"machine": {
"batch_type": "pbs",
"context_type": "local",
"machine_type": "shell",
"local_root": "./",
"remote_root": "../work/"
},
"resources": {
"number_node": 1,
"cpu_per_node": 16,
"_gpu_per_node": 0,
"queue_name": "gpuQ",
"group_size": 1,
"custom_flags": [
"#PBS -N lmp",
"#PBS -l walltime=30:00:00:00",
"#PBS -W x=GRES:gpu@4",
"#PBS -S /bin/bash",
"#PBS -V",
"source activate deepmd3",
"export OMP_NUM_THREADS=4",
"export TF_INTRA_OP_PARALLELISM_THREADS=4",
"export TF_INTER_OP_PARALLELISM_THREADS=2"
]
}
}
],
"fp": [
{
"command": "mpirun -genv I_MPI_DEVICE rdma -machinefile /tmp/nodefile.$$ -n $NP /opt/software/vasp/vasp-6.3.0/bin/vasp_std >vasp.out",
"machine": {
"batch_type": "PBS",
"context_type": "local",
"machine_type": "shell",
"local_root": "./",
"remote_root": "../work/"
},
"resources": {
"number_node": 1,
"cpu_per_node": 40,
"_gpu_per_node": 0,
"queue_name": "six_hours",
"group_size": 1,
"custom_flags": [
"#PBS -N vasp",
"#PBS -l walltime=30:00:00:00",
"#PBS -S /bin/bash",
"#PBS -V",
"cd $PBS_O_WORKDIR",
"source /opt/intel/impi/2018.1.163/bin64/mpivars.sh",
"source /opt/intel/compilers_and_libraries_2018/linux/bin/compilervars.sh intel64",
"source /opt/intel/mkl/bin/mklvars.sh intel64"
]
}
}
]
}parma.json
{
"type_map": ["Bi"],
"mass_map": [208.98],
"init_data_prefix": "../init/",
"init_data_sys": ["Bi-pmn21-551-500-train-data", "Bi-pmna-551-500-train-data"],
"sys_configs_prefix": "../init/",
"train_backend":"tensorflow",
"sys_configs": [
["POSCAR-pmn21-551", "POSCAR-pmna-551"],
["POSCAR-pmn21-551"],
["POSCAR-pmna-551"]
],
"_comment": " that's all ",
"numb_models": 4,
"default_training_param": {
"model": {
"type_map": ["Bi"],
"descriptor": {
"type": "se_e2_a",
"sel": [25],
"rcut_smth": 0.5,
"rcut": 6.0,
"neuron": [25, 50, 100],
"resnet_dt": true,
"axis_neuron": 12,
"seed": 1,
"_precision": "float32"
},
"fitting_net": {
"neuron": [240, 240, 240],
"resnet_dt": true,
"seed": 1,
"_precision": "float32"
}
},
"learning_rate": {
"type": "exp",
"start_lr": 0.001,
"stop_lr": 1.0e-8,
"decay_steps": 100
},
"loss": {
"start_pref_e": 0.02,
"limit_pref_e": 1,
"start_pref_f": 1000,
"limit_pref_f": 1,
"start_pref_v": 0.02,
"limit_pref_v": 1
},
"training": {
"_set_prefix": "set",
"stop_batch": 400000,
"training_data": {
"batch_size": "auto"
},
"seed": 1,
"disp_file": "lcurve.out",
"disp_freq": 1000,
"_numb_test": 4,
"save_freq": 1000,
"save_ckpt": "model.ckpt",
"disp_training": true,
"time_training": true,
"profiling": false,
"profiling_file": "timeline.json",
"_comment": "that's all"
}
},
"model_devi_dt": 0.001,
"model_devi_skip": 0,
"model_devi_f_trust_lo": 0.05,
"model_devi_f_trust_hi": 0.15,
"_model_devi_e_trust_lo": 10000000000.0,
"_model_devi_e_trust_hi": 10000000000.0,
"model_devi_clean_traj": false,
"model_devi_jobs": [
{
"sys_idx": [1],
"temps": [600, 500, 400, 300, 200, 100, 50],
"press": [1.0, 10, 100, 1000, 10000, 20000, 50000],
"trj_freq": 10,
"nsteps": 1000,
"ensemble": "npt",
"_idx": "00"
},
{
"sys_idx": [2],
"temps": [600, 500, 400, 300, 200, 100, 50],
"press": [1.0, 10, 100, 1000, 10000, 20000, 50000],
"trj_freq": 10,
"nsteps": 3000,
"ensemble": "npt",
"_idx": "01"
},
{
"sys_idx": [0, 1,2],
"temps": [600, 500, 400, 300, 200, 100, 50],
"press": [1.0, 10, 100, 1000, 10000, 20000, 50000],
"trj_freq": 10,
"nsteps": 5000,
"ensemble": "npt",
"_idx": "01"
}
],
"fp_style": "vasp",
"shuffle_poscar": false,
"fp_task_max": 10,
"fp_task_min": 5,
"fp_pp_path": "./",
"fp_pp_files": ["POTCAR"],
"fp_incar": "./INCAR_vasp"
}dpgen运行
source activate deepmd
dpgen run param.json machine.json >> dpgen.log 2>&1以下摘自官方文档
Workflow of the DP-GEN
深度势能生成器(DeeP Potential GENerator,DP-GEN)是一个实现并发学习方案以生成可靠深度势能(DP)模型的软件包。通常,DP-GEN 的工作流程包含三个过程:初始化(init)、运行(run)和自动测试(autotest)。
- 初始化(init):通过第一性原理计算生成初始训练数据集。
- 运行(run):DP-GEN 的主要过程,在此过程中训练数据集得到丰富,DP 模型的质量自动得到提高。
- 自动测试(autotest):计算一组简单的性质和/或进行测试,以与密度泛函理论(DFT)和/或经验原子间势能进行比较。
param.json
param.json 中的关键字可以分为 4 部分:
- 系统和数据:用于指定原子类型、初始数据等。
- 训练:主要用于指定训练步骤中的任务。
- 探索:主要用于指定标记步骤中的任务。
- 标记:主要用于指定标记步骤中的任务。
这里我们以气相甲烷分子为例介绍 param.json 中的主要关键字。
系统和数据
与系统和数据相关的关键字如下:
**"type_map"**: ["H","C"],
**"mass_map"**: [1,12],
**"init_data_prefix"**: "../",
**"init_data_sys"**: ["init/CH4.POSCAR.01x01x01/02.md/sys-0004-0001/deepmd"],
**"sys_configs_prefix"**: "../",
**"sys_configs"**: [
["init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000*/POSCAR"],
["init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00001*/POSCAR"]
],
**"_comment"**: " that's all ",关键字说明:
| 关键字 | 类型 | 说明 |
|---|---|---|
| “type_map” | list | 原子类型 |
| “mass_map” | list | 标准原子质量。 |
| “init_data_prefix” | string | 初始数据目录的前缀。 |
| “init_data_sys” | list | 初始数据的目录。你可以在此处使用绝对路径或相对路径。 |
| “sys_configs_prefix” | string | sys_configs 的前缀。 |
| “sys_configs” | list | 包含在迭代中要探索的结构的目录。这里支持通配符。 |
示例说明:
与系统相关的关键字指定了系统的基本信息。“type_map”给出了原子类型,即“H”和“C”。“mass_map”给出了标准原子质量,即“1”和“12”。
与数据相关的关键字指定了用于训练初始深度势能(DP)模型的初始数据以及用于模型偏差计算的结构。“init_data_prefix”和“init_data_sys”指定了初始数据的位置。“sys_configs_prefix”和“sys_configs”指定了结构的位置。在这里,初始数据在“…… /init/CH4.POSCAR.01x01x01/02.md/sys-0004-0001/deepmd”提供。这些结构分为两组,并在“……/init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000*/POSCAR”和“……/init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00001*/POSCAR”提供。
训练
与训练相关的关键字如下: https://docs.deepmodeling.com/projects/deepmd/en/master/train-input-auto.html#model-descriptor-type
fitting_net param
model/fitting_net 配置参数用于拟合物理属性,并根据 type 参数的不同接受不同的子参数。以下是对各选项的详细解释:
type 参数
- 路径:
model/fitting_net/type - 类型:
str - 默认值:
ener - 可选值:
ener,dipole,polar ener: 拟合能量模型(势能面)。dipole: 拟合原子偶极矩模型。需要在数据系统中提供dipole.npy文件。polar: 拟合原子极化率模型。需要在数据系统中提供polarizability.npy文件。
ener 模型配置参数
numb_fparam- 类型:
int - 默认值:
0 - 描述: 帧参数的维度。如果大于0,则需要包含
fparam.npy文件来提供输入参数。
- 类型:
numb_aparam- 类型:
int - 默认值:
0 - 描述: 原子参数的维度。如果大于0,则需要包含
aparam.npy文件来提供输入参数。
- 类型:
neuron- 类型:
list - 默认值:
[120, 120, 120] - 描述: 拟合网络中每个隐藏层的神经元数量。当两个隐藏层的大小相同时,将构建一个跳跃连接(skip connection)。
- 类型:
activation_function- 类型:
str - 默认值:
tanh - 描述: 拟合网络中的激活函数。支持的激活函数包括
relu,relu6,softplus,sigmoid,tanh,gelu。
- 类型:
precision- 类型:
str - 默认值:
float64 - 描述: 拟合网络参数的精度。支持的选项包括
default,float16,float32,float64。
- 类型:
resnet_dt- 类型:
bool - 默认值:
True - 描述: 是否在跳跃连接中使用时间步长(timestep)。
- 类型:
trainable- 类型:
list | bool - 默认值:
True - 描述: 是否使拟合网络中的参数可训练。可以是一个布尔值或一个布尔值列表。
- 类型:
rcond- 类型:
float - 默认值:
0.001 - 描述: 用于确定每种类型原子的初始能量偏移的条件数。
- 类型:
seed- 类型:
int | NoneType - 描述: 用于初始化拟合网络参数的随机种子。
- 类型:
atom_ener- 类型:
list - 默认值:
[] - 描述: 指定每种类型原子在真空中的能量。
- 类型:
dipole 模型配置参数
与 ener 模型相似,但涉及偶极矩的拟合。参数如 neuron、activation_function 等配置相同。
polar 模型配置参数
与 ener 模型相似,但涉及极化率的拟合。
**"numb_models"**: 4,
**"default_training_param"**: {
**"model"**: {
**"type_map"**: ["H","C"],
**"descriptor"**: {
//The type of the descriptor is set to "se_a"
**"type"**: "se_a",
//“sel”给出了截断半径内的最大可能邻居数量。它是一个列表,其长度与系统中的原子类型数量相同,并且“sel[i]”表示类型为 i 的最大可能邻居数量。
**"sel"**: [16,4],
//“rcut_smth”给出平滑开始的位置。
**"rcut_smth"**: 0.5,
//“rcut”是用于近邻搜索的截断半径
**"rcut"**: 5.0,
//该**neuron**指定了嵌入网络的大小。从左到右,成员分别表示从输入端到输出端每个隐藏层的大小。如果外层的大小是内层的两倍,则会将内层复制并连接在一起,并在它们之间构建一个ResNet架构。
**"neuron"**: [120,120,120],
// 如果选项 `resnet_dt` 设置为 true,则在 ResNet 中会使用时间步长 (timestep)。
**"resnet_dt"**: **true**,
// `axis_neuron` 指定了嵌入矩阵中子矩阵的大小,即 DeepPot-SE 论文中所解释的轴矩阵 (axis matrix)。
**"axis_neuron"**: 12,
//`seed` 用于提供随机种子,在初始化模型参数时生成随机数。
**"seed"**: 1
},
**"fitting_net"**: {
**"neuron"**: [25,50,100],
**"resnet_dt"**: **false**,
**"seed"**: 1
}
},
**"learning_rate"**: {
**"type"**: "exp",
**"start_lr"**: 0.001,
**"decay_steps"**: 5000
},
**"loss"**: {
**"start_pref_e"**: 0.02,
**"limit_pref_e"**: 2,
**"start_pref_f"**: 1000,
**"limit_pref_f"**: 1,
**"start_pref_v"**: 0.0,
**"limit_pref_v"**: 0.0
},
**"training"**: {
**"stop_batch"**: 400000,
**"disp_file"**: "lcurve.out",
**"disp_freq"**: 1000,
**"numb_test"**: 4,
**"save_freq"**: 1000,
**"save_ckpt"**: "model.ckpt",
**"disp_training"**: **true**,
**"time_training"**: **true**,
**"profiling"**: **false**,
**"profiling_file"**: "timeline.json",
**"_comment"**: "that's all"
}
},关键字说明:
| 关键字 | 类型 | 说明 |
|---|---|---|
| “numb_models” | int | 在 00.train 中要训练的模型数量。 |
| “default_training_param” | dict | DeePMD-kit 的训练参数。 |
示例说明:
与训练相关的关键字指定了训练任务的细节。“numb_models”指定了要训练的模型数量。“default_training_param”指定了 DeePMD-kit 的训练参数。在这里,将训练 4 个深度势能(DP)模型。
DP-GEN 的训练部分由 DeePMD-kit 执行,因此这里的关键字与 DeePMD-kit 的关键字相同,这里不再解释。这些关键字的详细解释可以在DeePMD-kit 的文档中找到。
探索
与探索相关的关键字如下:
**"model_devi_dt"**: 0.002,
**"model_devi_skip"**: 0,
**"model_devi_f_trust_lo"**: 0.05,
**"model_devi_f_trust_hi"**: 0.15,
**"model_devi_e_trust_lo"**: 10000000000.0,
**"model_devi_e_trust_hi"**: 10000000000.0,
**"model_devi_clean_traj"**: **true**,
**"model_devi_jobs"**: [
{**"sys_idx"**: [0],**"temps"**: [100],**"press"**: [1.0],**"trj_freq"**: 10,**"nsteps"**: 300,**"ensemble"**: "nvt",**"_idx"**: "00"},
{**"sys_idx"**: [1],**"temps"**: [100],**"press"**: [1.0],**"trj_freq"**: 10,**"nsteps"**: 3000,**"ensemble"**: "nvt",**"_idx"**: "01"}
],关键字描述:
| Key | Type | |
|---|---|---|
| “model_devi_dt” | float | 分子动力学的时间步长。 |
| “model_devi_skip” | int | 在每次分子动力学中跳过的用于力场计算的结构数量。 |
| “model_devi_f_trust_lo” | float | 力的选择下限。如果是列表,则应分别为“sys_configs”中的每个索引设置。 |
| “model_devi_f_trust_hi” | int | 力的选择上限。如果是列表,则应分别为“sys_configs”中的每个索引设置。 |
| “model_devi_v_trust_lo” | float or list | 选择的压力张量的下限。如果是列表,则应分别为“sys_configs”中的每个索引设置。应与 DeePMD-kit v2.x 一起使用。 |
| “model_devi_v_trust_hi” | float or list | 选择的压力张量的上限。如果是列表,则应分别为“sys_configs”中的每个索引设置。应与 DeePMD-kit v2.x 一起使用。 |
| “model_devi_clean_traj” | bool or int | 如果“model_devi_clean_traj”的类型是布尔类型,则它表示是否清理分子动力学中的轨迹文件夹,因为它们太大了。如果它是整数类型,则将保留最近的 n 次迭代的轨迹文件夹,其他的将被删除。 |
| “model_devi_jobs” | list | 在 01.model_devi 中的探索设置。列表中的每个字典对应一次迭代。“model_devi_jobs”的索引与迭代的索引完全一致。 |
| “sys_idx” | List of integer | 要选择作为分子动力学的初始结构并进行探索的系统。索引与“sys_configs”完全对应。 |
| “temps” | list | 分子动力学中的温度(K)。 |
| “press” | list | 分子动力学中的压力(Bar)。 |
| “trj_freq” | int | 分子动力学中保存轨迹的频率。 |
| “nsteps” | int | 分子动力学的运行步数。 |
| “ensembles” | str | 确定在分子动力学中使用哪种系综,选项包括“npt”和“nvt”。 |
示例说明:
与探索相关的关键字指定了探索任务的细节。在这里,在 nvt 系综下,以 100 K 的温度和 1.0 Bar 的压力进行分子动力学模拟,积分器时间为 2 fs。在“model_devi_jobs”中设置了两次迭代。在第 00 和 01 次迭代中,分别使用“sys_configs”中的第一组和第二组结构进行 300 和 3000 个时间步长的分子动力学模拟。我们选择保存分子动力学模拟中生成的所有结构,并将“trj_freq”设置为 10,因此在第 00 和 01 次迭代中分别保存了 30 和 300 个结构。如果保存的结构的“max_devi_f”落在 0.05 和 0.15 之间,DP-GEN 将把该结构视为候选结构。我们选择清理分子动力学中的轨迹文件夹,因为它们太大了。如果你想保留最近的 n 次迭代的轨迹文件夹,可以将“model_devi_clean_traj”设置为一个整数。
标记
与标记相关的关键字如下:
**"fp_style"**: "vasp",
**"shuffle_poscar"**: **false**,
**"fp_task_max"**: 20,
**"fp_task_min"**: 5,
**"fp_pp_path"**: "./",
**"fp_pp_files"**: ["POTCAR_H","POTCAR_C"],
**"fp_incar"**: "./INCAR_methane"关键字描述:
| Key | Type | |
|---|---|---|
| “fp_style” | String | 第一性原理计算软件。目前选项包括“vasp”、“pwscf”、“siesta”和“gaussian”。 |
| “shuffle_poscar” | Boolean | |
| “fp_task_max” | Integer | 每次迭代中在 02.fp 中要计算的结构的最大数量。 |
| “fp_task_min” | Integer | 每次迭代中在 02.fp 中要计算的结构的最小数量。 |
| “fp_pp_path” | String | 用于 02.fp 的赝势文件所在的目录。 |
| “fp_pp_files” | List of string | 用于 02.fp 的赝势文件。注意,元素的顺序应与 type_map 中的顺序相对应。 |
| “fp_incar” | String | VASP 的输入文件。INCAR 必须指定 KSPACING 和 KGAMMA。 |
示例说明:
与标记相关的关键字指定了标记任务的细节。在这里,每次迭代中,将使用 VASP 代码对最少 1 个、最多 20 个结构进行标记,INCAR 文件位于“……/INCAR_methane”,赝势文件 POTCAR 位于“……/methane/POTCAR”。请注意,POSCAR 和 POTCAR 中元素的顺序应与type_map中的顺序相对应。
machine.json
DP-GEN 的运行过程中的每次迭代由三个步骤组成:探索、标记和训练。相应地,machine.json 由三部分组成:train、model_devi 和 fp。每一部分都是一个字典列表。每个字典可以被视为一个独立的计算环境。
在本节中,我们将向你展示如何使用新的 DPDispatcher(关键字“api_version”的值大于或等于 1.0)在本地工作站执行训练步骤、在本地 Slurm 集群执行 model_devi 步骤以及在远程 PBS 集群执行 fp 步骤。对于每个步骤,需要三种类型的关键字:
- 命令:提供用于执行每个步骤的命令。
- 机器:指定机器环境(本地工作站、本地或远程集群,或云服务器)。
- 资源:指定组数、节点数、CPU 和 GPU 的数量;启用虚拟环境。
在本地工作站执行训练步骤
在这个例子中,我们在本地工作站上执行训练步骤。
**"train"**: [
{
**"command"**: "dp",
**"machine"**: {
**"batch_type"**: "Shell",
**"context_type"**: "local",
**"local_root"**: "./",
**"remote_root"**: "/home/user1234/work_path"
},
**"resources"**: {
**"number_node"**: 1,
**"cpu_per_node"**: 4,
**"gpu_per_node"**: 1,
**"group_size"**: 1,
**"source_list"**: ["/home/user1234/deepmd.env"]
}
}
],关键字描述:
| 关键字 | 类型 | 说明 |
|---|---|---|
| “command” | String | 此任务要执行的命令。 |
| “machine” | dict | 机器的定义。 |
| “batch_type” | str | 批处理作业系统类型。 |
| “context_type” | str | 用于连接远程机器的方式。 |
| “local_root” | str | 任务及相关文件所在的目录。 |
| “remote_root” | str | 任务在远程机器上执行的目录。 |
| “machine” | dict | 资源的定义。 |
| “number_node” | int | 每个作业所需的节点数量。 |
| “cpu_per_node” | int | 分配给每个作业的每个节点的 CPU 数量。 |
| “gpu_per_node” | int | 分配给每个作业的每个节点的 GPU 数量。 |
| “group_size” | int | 一个作业中的任务数量。 |
| “source_list” | str | 任务在远程机器上执行的目录。 |
示例说明:
DeePMD-kit 中训练任务的“command”是“dp”。
在机器参数中,“batch_type”指定作业调度系统的类型。如果没有作业调度系统,我们可以使用“Shell”来执行任务。“context_type”指定数据传输的方法,“local”意味着通过本地文件存储系统(例如 cp、mv 等)复制和移动数据。在 DP-GEN 中,所有任务的路径都由软件自动定位和设置,因此“local_root”始终设置为“./”。每个任务的输入文件将被发送到“remote_root”,并且任务将在那里执行,所以我们需要确保该路径存在。
在资源参数中,“number_node”、“cpu_per_node”和“gpu_per_node”分别指定一个任务所需的节点数量、每个节点的 CPU 数量和每个节点的 GPU 数量。需要强调的是“group_size”,它指定将多少个任务打包到一个组中。在训练任务中,我们需要训练 4 个模型。如果我们只有一个 GPU,我们可以将“group_size”设置为 4。如果“group_size”设置为 1,由于没有作业调度系统,4 个模型将在一个 GPU 上同时训练。最后,可以通过“source_list”激活环境变量。在这个例子中,在执行“dp”之前执行“source /home/user1234/deepmd.env”以加载执行训练任务所需的环境变量。
在本地 Slurm 集群执行 model_devi 步骤
在这个例子中,我们在本地 Slurm 工作站上执行 model_devi 步骤。
**"model_devi"**: [
{
**"command"**: "lmp",
**"machine"**: {
**"context_type"**: "local",
**"batch_type"**: "Slurm",
**"local_root"**: "./",
**"remote_root"**: "/home/user1234/work_path"
},
**"resources"**: {
**"number_node"**: 1,
**"cpu_per_node"**: 4,
**"gpu_per_node"**: 1,
**"queue_name"**: "QueueGPU",
**"custom_flags"** : ["#SBATCH --mem=32G"],
**"group_size"**: 10,
**"source_list"**: ["/home/user1234/lammps.env"]
}
}
],关键字描述:
| 关键字 | 类型 | 说明 |
|---|---|---|
| “queue_name” | String | 批处理作业调度系统的队列名称。 |
| “custom_flags” | String | 传递给作业提交脚本头部的额外行。 |
示例说明:
LAMMPS中model_devi任务的“command”是“lmp”。
在机器参数中,我们通过将“batch_type”更改为“Slurm”来指定作业调度系统的类型。
在资源参数中,我们通过添加“queue_name”来指定任务提交到的队列名称。我们可以通过“custom_flags”向计算脚本添加额外的行。在model_devi步骤中,通常有很多短任务,所以我们通常将多个任务(例如10个)打包成一组进行提交。其他参数与本地工作站的类似。
在远程PBS集群中执行fp步骤
在这个例子中,我们在一个可以通过SSH访问的远程PBS集群上执行fp步骤。
**"fp"**: [
{
**"command"**: "mpirun -n 32 vasp_std",
**"machine"**: {
**"context_type"**: "SSHContext",
**"batch_type"**: "PBS",
**"local_root"**: "./",
**"remote_root"**: "/home/user1234/work_path",
**"remote_profile"**: {
**"hostname"**: "39.xxx.xx.xx",
**"username"**: "user1234"
}
},
**"resources"**: {
**"number_node"**: 1,
**"cpu_per_node"**: 32,
**"gpu_per_node"**: 0,
**"queue_name"**: "QueueCPU",
**"group_size"**: 5,
**"source_list"**: ["/home/user1234/vasp.env"]
}
}
],关键字描述:
| 关键字 | 类型 | 说明 |
|---|---|---|
| “remote_profile” | 字典 | 用于维持与远程机器连接的信息。 |
| “hostname” | 字符串 | SSH 连接的主机名或 IP 地址。 |
| “username” | 字符串 | 目标 Linux 系统的用户名。 |
示例说明:
对于 fp 任务使用 VASP 代码,并且使用 mpi 进行并行计算,所以添加“mpirun -n 32”以指定并行线程的数量。
在机器参数中,将“context_type”修改为“SSHContext”,将“batch_type”修改为“PBS”。值得注意的是,“remote_root”应设置为远程 PBS 集群上可访问的路径。添加“remote_profile”以指定用于连接远程集群的信息,包括主机名、用户名、密码、端口等。
在资源参数中,我们将“gpu_per_node”设置为 0,因为对于 VASP 计算使用 CPU 更具成本效益。
Results analysis
用户需要了解运行过程的输出文件以及它们所包含的信息。在成功执行上述命令后,我们可以发现在 dpgen_example/run 中会自动生成一个文件夹和两个文件。
$ ls
dpgen.log INCAR_methane iter.000000 machine.json param.json record.dpgeniter.000000包含了 DP-GEN 在第一次迭代中生成的主要结果。record.dpgen记录了运行过程的当前阶段。dpgen.log包括时间和迭代信息。当第一次迭代完成时,iter.000000的文件夹结构如下:
$ tree iter.000000/ -L 1
./iter.000000/
├── 00.train
├── 01.model_devi
└── 02.fp- 00.train:在现有数据上训练若干个(默认是 4 个)深度势能模型。
- 01.model_devi:使用在 00.train 中获得的深度势能模型生成新的构型。
- 02.fp:对选定的构型进行第一性原理计算,并将结果转换为训练数据。
00.train 首先,我们查看文件夹iter.000000/00.train。
$ tree iter.000000/00.train -L 1
./iter.000000/00.train/
├── 000
├── 001
├── 002
├── 003
├── data.init -> /root/dpgen_example
├── data.iters
├── graph.000.pb -> 000/frozen_model.pb
├── graph.001.pb -> 001/frozen_model.pb
├── graph.002.pb -> 002/frozen_model.pb
└── graph.003.pb -> 003/frozen_model.pb- 文件夹 00x 包含 DeePMD-kit 的输入和输出文件,在其中训练一个模型。
- graph.00x.pb,链接到 00x/frozen.pb,是 DeePMD-kit 生成的模型。这些模型之间的唯一区别是神经网络初始化的随机种子。我们可以随机选择其中一个,比如 000。
$ tree iter.000000/00.train/000 -L 1
./iter.000000/00.train/000
├── checkpoint
├── frozen_model.pb
├── input.json
├── lcurve.out
├── model.ckpt-400000.data-00000-of-00001
├── model.ckpt-400000.index
├── model.ckpt-400000.meta
├── model.ckpt.data-00000-of-00001
├── model.ckpt.index
├── model.ckpt.meta
└── train.loginput.json是当前任务的 DeePMD-kit 设置文件。checkpoint用于重新开始训练。model.ckpt*是与模型相关的文件。frozen_model.pb是冻结的模型。lcurve.out记录能量和力的训练精度。train.log包括版本、数据、硬件信息、时间等。
01.model_devi 然后,我们查看文件夹 iter.000000/01.model_devi。
$ tree iter.000000/01.model_devi -L 1
./iter.000000/01.model_devi/
├── confs
├── graph.000.pb -> /root/dpgen_example/run/iter.000000/00.train/graph.000.pb
├── graph.001.pb -> /root/dpgen_example/run/iter.000000/00.train/graph.001.pb
├── graph.002.pb -> /root/dpgen_example/run/iter.000000/00.train/graph.002.pb
├── graph.003.pb -> /root/dpgen_example/run/iter.000000/00.train/graph.003.pb
├── task.000.000000
├── task.000.000001
├── task.000.000002
├── task.000.000003
├── task.000.000004
├── task.000.000005
├── task.000.000006
├── task.000.000007
├── task.000.000008
└── task.000.000009- 文件夹“confs”包含从你在 param.json 的“sys_configs”中设置的 POSCAR 转换而来的用于 LAMMPS 分子动力学模拟的初始构型。
- 文件夹“task.000.00000x”包含 LAMMPS 的输入和输出文件。我们可以随机选择其中一个,比如“task.000.000001”。
$ tree iter.000000/01.model_devi/task.000.000001
./iter.000000/01.model_devi/task.000.000001
├── conf.lmp -> ../confs/000.0001.lmp
├── input.lammps
├── log.lammps
├── model_devi.log
└── model_devi.outconf.lmp,链接到文件夹“confs”中的000.0001.lmp,用作分子动力学模拟的初始构型。input.lammps是 LAMMPS 的输入文件。model_devi.out记录了分子动力学模拟中有关标签(能量和力)的模型偏差。它用作选择哪些结构进行第一性原理计算的标准。
通过查看model_devi.out的开头部分,你会看到:
$ head -n 5 ./iter.000000/01.model_devi/task.000.000001/model_devi.out
# step max_devi_v min_devi_v avg_devi_v max_devi_f min_devi_f avg_devi_f
0 1.438427e-04 5.689551e-05 1.083383e-04 8.835352e-04 5.806717e-04 7.098761e-04
10 3.887636e-03 9.377374e-04 2.577191e-03 2.880724e-02 1.329747e-02 1.895448e-02
20 7.723417e-04 2.276932e-04 4.340100e-04 3.151907e-03 2.430687e-03 2.727186e-03
30 4.962806e-03 4.943687e-04 2.925484e-03 5.866077e-02 1.719157e-02 3.011857e-02现在我们将重点关注max_devi_f。回想一下,我们已将"trj_freq"设置为10,所以每10步就会保存结构。是否选择该结构取决于它的"max_devi_f"。如果它在"model_devi_f_trust_lo"(0.05)和"model_devi_f_trust_hi"(0.15)之间,DP-GEN将把该结构视为候选结构。在这里,只有第30个结构会被选中,它的"max_devi_f"是5.866077e-02。
02.fp 最后,我们查看文件夹 iter.000000/02.fp。
$ tree iter.000000/02.fp -L 1
./iter.000000/02.fp
├── data.000
├── task.000.000000
├── task.000.000001
├── task.000.000002
├── task.000.000003
├── task.000.000004
├── task.000.000005
├── task.000.000006
├── task.000.000007
├── task.000.000008
├── task.000.000009
├── task.000.000010
├── task.000.000011
├── candidate.shuffled.000.out
├── POTCAR.000
├── rest_accurate.shuffled.000.out
└── rest_failed.shuffled.000.outPOTCAR是根据 param.json 的"fp_pp_files"生成的 VASP 输入文件。candidate.shuffle.000.out记录了从上一步 01.model_devi 中哪些结构将被选中。通常候选结构的数量远多于你期望一次计算的最大数量。在这种情况下,DP-GEN 将随机选择最多"fp_task_max"个结构并形成 task.*文件夹。rest_accurate.shuffle.000.out记录了其他模型准确的结构(“max_devi_f”小于"model_devi_f_trust_lo",无需再进行计算)。rest_failed.shuffled.000.out记录了其他模型不准确的结构(大于"model_devi_f_trust_hi",可能存在一些错误)。data.000:在第一性原理计算后,DP-GEN 将收集这些数据并将其转换为 DeePMD-kit 需要的格式。在下次迭代的00.train中,这些数据将与初始数据一起被训练。
通过执行“cat candidate.shuffled.000.out | grep task.000.000001”,你会看到:
$ cat ./iter.000000/02.fp/candidate.shuffled.000.out | grep task.000.000001
iter.000000/01.model_devi/task.000.000001 190
iter.000000/01.model_devi/task.000.000001 130
iter.000000/01.model_devi/task.000.000001 120
iter.000000/01.model_devi/task.000.000001 150
iter.000000/01.model_devi/task.000.000001 280
iter.000000/01.model_devi/task.000.000001 110
iter.000000/01.model_devi/task.000.000001 30
iter.000000/01.model_devi/task.000.000001 230task.000.000001 的第 30 个正是我们刚刚在 01.model_devi 中找到的满足再次进行计算标准的那个。在第一次迭代后,我们检查 dpgen.log 和 record.dpgen 的内容。
$ cat dpgen.log
2022-03-07 22:12:45,447 - INFO : start running
2022-03-07 22:12:45,447 - INFO : =============================iter.000000==============================
2022-03-07 22:12:45,447 - INFO : -------------------------iter.000000 task 00--------------------------
2022-03-07 22:12:45,451 - INFO : -------------------------iter.000000 task 01--------------------------
2022-03-08 00:53:00,179 - INFO : -------------------------iter.000000 task 02--------------------------
2022-03-08 00:53:00,179 - INFO : -------------------------iter.000000 task 03--------------------------
2022-03-08 00:53:00,187 - INFO : -------------------------iter.000000 task 04--------------------------
2022-03-08 00:57:04,113 - INFO : -------------------------iter.000000 task 05--------------------------
2022-03-08 00:57:04,113 - INFO : -------------------------iter.000000 task 06--------------------------
2022-03-08 00:57:04,123 - INFO : system 000 candidate : 12 **in** 310 3.87 %
2022-03-08 00:57:04,125 - INFO : system 000 failed : 0 **in** 310 0.00 %
2022-03-08 00:57:04,125 - INFO : system 000 accurate : 298 **in** 310 96.13 %
2022-03-08 00:57:04,126 - INFO : system 000 accurate_ratio: 0.9613 thresholds: 1.0000 and 1.0000 eff. task min and max -1 20 number of fp tasks: 12
2022-03-08 00:57:04,154 - INFO : -------------------------iter.000000 task 07--------------------------
2022-03-08 01:02:07,925 - INFO : -------------------------iter.000000 task 08--------------------------
2022-03-08 01:02:07,926 - INFO : failed tasks: 0 **in** 12 0.00 %
2022-03-08 01:02:07,949 - INFO : failed frame: 0 **in** 12 0.00 %可以发现,在 iter.000000 中生成了 310 个结构,其中有 12 个结构被收集用于第一性原理计算。
$ cat record.dpgen
0 0
0 1
0 2
0 3
0 4
0 5
0 6
0 7
0 8每一行包含两个数字:第一个是迭代的索引,第二个数字范围从0到9,记录了每次迭代中当前正在运行的阶段。
| Index of iterations | “Stage in each iteration “ | Process |
|---|---|---|
| 0 | 0 | make_train |
| 0 | 1 | run_train |
| 0 | 2 | post_train |
| 0 | 3 | make_model_devi |
| 0 | 4 | run_model_devi |
| 0 | 5 | post_model_devi |
| 0 | 6 | make_fp |
| 0 | 7 | run_fp |
| 0 | 8 | post_fp |
如果 DP-GEN 的进程由于某种原因停止,DP-GEN 将通过 record.dpgen 自动恢复主进程。你也可以根据自己的目的手动更改它,例如删除最后几次迭代并从一个检查点恢复。在所有迭代完成后,我们检查 dpgen_example/run 的结构。
$ tree ./ -L 2
./
├── dpgen.log
├── INCAR_methane
├── iter.000000
│ ├── 00.train
│ ├── 01.model_devi
│ └── 02.fp
├── iter.000001
│ ├── 00.train
│ ├── 01.model_devi
│ └── 02.fp
├── iter.000002
│ └── 00.train
├── machine.json
├── param.json
└── record.dpgen以及 dpgen.log 的内容。
$ cat cat dpgen.log | grep system
2022-03-08 00:57:04,123 - INFO : system 000 candidate : 12 **in** 310 3.87 %
2022-03-08 00:57:04,125 - INFO : system 000 failed : 0 **in** 310 0.00 %
2022-03-08 00:57:04,125 - INFO : system 000 accurate : 298 **in** 310 96.13 %
2022-03-08 00:57:04,126 - INFO : system 000 accurate_ratio: 0.9613 thresholds: 1.0000 and 1.0000 eff. task min and max -1 20 number of fp tasks: 12
2022-03-08 03:47:00,718 - INFO : system 001 candidate : 0 **in** 3010 0.00 %
2022-03-08 03:47:00,718 - INFO : system 001 failed : 0 **in** 3010 0.00 %
2022-03-08 03:47:00,719 - INFO : system 001 accurate : 3010 **in** 3010 100.00 %
2022-03-08 03:47:00,722 - INFO : system 001 accurate_ratio: 1.0000 thresholds: 1.0000 and 1.0000 eff. task min and max -1 0 number of fp tasks: 0可以发现,在 iter.000001 中生成了 3010 个结构,其中没有结构被收集用于第一性原理计算。因此,在 iter.000002/00.train 中最终的模型没有被更新。
Simplify
当你有一个包含大量重复数据的数据集时,这个步骤将帮助你简化你的数据集。由于dpgen simplify是在一个大型数据集上执行的,所以在这部分只提供一个简单的示例。
要了解更多关于简化的内容,你可以参考DPGEN 的文档、dpgen simplify 参数文档、dpgen simplify 机器参数文档。
这个示例可以从 dpgen/examples/simplify-MAPbI3-scan-lebesgue 下载。你可以在dpgen.examples中找到更多示例。
在这个例子中,data包含一个基于 MAPbI3-scan 案例的简化数据集。由于它已经被极大地简化了,所以不要太当真。它只是一个示例。simplify_example是工作路径,其中包含INCAR以及simplify.json和machine.json的模板。你可以在这里使用命令nohup dpgen simplify simplify.json machine.json 1>log 2>err &来测试dpgen simplify是否能正常运行。
温馨提醒:
machine.json由dpdispatcher 0.4.15支持,请查看 https://docs.deepmodeling.com/projects/dpdispatcher/en/latest/,根据你的dpdispatcher版本更新参数。POTCAR应该由用户准备。- 请检查路径和文件名,确保它们是正确的。
简化可以在迁移学习中使用,参见案例研究:迁移学习。
Auto-test
“自动测试”(auto-test)功能仅适用于合金材料,用于验证其深度势能(DP)模型的准确性,用户可以计算一组简单的性质,并将结果与密度泛函理论(DFT)或传统经验力场的结果进行比较。DPGEN 的自动测试模块支持多种性质的计算,例如:
- 00.equi(默认任务):平衡状态;
- 01.eos:状态方程;
- 02.elastic:弹性,如杨氏模量;
- 03.vacancy:空位形成能;
- 04.interstitial:间隙形成能;
- 05.surf:表面形成能。
在这部分中,以 Al-Mg-Cu 的深度势能为例来说明如何自动测试合金材料的深度势能。每个“auto-test”任务包括三个阶段:
- “
make”自动准备所有所需的计算文件和输入脚本; - “
run”可以帮助将计算任务提交到远程计算平台,并且当计算任务完成时,会自动收集结果; - “
post”自动将计算结果返回到本地根目录。
structure relaxation
step1-make
在一个单独的文件夹中准备以下文件。
├── machine.json
├── relaxation.json
├── confs
│ ├── mp-3034重要! ID 编号 mp-3034 与 Al-Mg-Cu 的材料项目 ID 一致。
为了利用pymatgen与材料项目结合的优势,通过材料项目 ID(mp-ID)自动生成计算任务的文件,你应该在.bashrc中添加材料项目的 API。
你可以通过运行以下命令轻松做到这一点。
vim .bashrc
// add this line into this file, `export MAPI_KEY="your-api-key-for-material-projects"`如果你对材料项目的 API 密钥不清楚,请参考这个[链接]https://materialsproject.org/api#:~:text=API Key,-Your API Key&text=To make any request to,anyone you do not trust.)。%E3%80%82)
- machine.json 与在“init”和“run”中使用的相同。关于它的更多信息,请查看这个链接。
- relaxtion.json。
{
**"structures"**: ["confs/mp-3034"],*//in this folder, confs/mp-3034, required files and scripts will be generated automatically by `dpgen autotest make relaxation.json`* **"interaction"**: {
**"type"**: "deepmd",
**"model"**: "graph.pb",
**"in_lammps"**: "lammps_input/in.lammps",
**"type_map"**: {**"Mg"**:0,**"Al"**: 1,**"Cu"**:2} *//if you calculate other materials, remember to modify element types here.* },
**"relaxation"**: {
**"cal_setting"**:{**"etol"**: 1e-12,
**"ftol"**: 1e-6,
**"maxiter"**: 5000,
**"maximal"**: 500000,
**"relax_shape"**: **true**,
**"relax_vol"**: **true**}
}
}运行这个命令:
dpgen autotest make relaxation.json然后将自动生成用于计算的相应文件和脚本。
step2-run
nohup dpgen autotest run relaxation.json machine.json &运行此命令后,结构将被弛豫。
step3-post
dpgen autotest post relaxation.jsonproperty calculation
step1-make
用于性质计算的参数在 property.json 文件中。
{
**"structures"**: ["confs/mp-3034"],
**"interaction"**: {
**"type"**: "deepmd",
**"model"**: "graph.pb",
**"deepmd_version"**:"2.1.0",
**"type_map"**: {**"Mg"**:0,**"Al"**: 1,**"Cu"**:2}
},
**"properties"**: [
{
**"type"**: "eos",
**"vol_start"**: 0.9,
**"vol_end"**: 1.1,
**"vol_step"**: 0.01
},
{
**"type"**: "elastic",
**"norm_deform"**: 2e-2,
**"shear_deform"**: 5e-2
},
{
**"type"**: "vacancy",
**"supercell"**: [3, 3, 3],
**"start_confs_path"**: "confs"
},
{
**"type"**: "interstitial",
**"supercell"**: [3, 3, 3],
**"insert_ele"**: ["Mg","Al","Cu"],
**"conf_filters"**:{**"min_dist"**: 1.5},
**"cal_setting"**: {**"input_prop"**: "lammps_input/lammps_high"}
},
{
**"type"**: "surface",
**"min_slab_size"**: 10,
**"min_vacuum_size"**:11,
**"max_miller"**: 2,
**"cal_type"**: "static"
}
]
}运行这个命令
dpgen autotest make property.jsonstep2-run
运行这个命令
nohup dpgen autotest run property.json machine.json &step3-post
dpgen autotest post property.json在该文件夹中,你可以使用命令“tree -L 1”,然后你可以查看结果。
(base) ➜ mp-3034 tree . -L 1
.
├── dpdispatcher.log
├── dpgen.log
├── elastic_00
├── eos_00
├── eos_00.bk000
├── eos_00.bk001
├── eos_00.bk002
├── eos_00.bk003
├── eos_00.bk004
├── eos_00.bk005
├── graph_new.pb
├── interstitial_00
├── POSCAR
├── relaxation
├── surface_00
└── vacancy_00- 01.eos:状态方程;
(base) ➜ mp-3034 tree eos_00 -L 1
eos_00
├── 99c07439f6f14399e7785dc783ca5a9047e768a8_flag_if_job_task_fail
├── 99c07439f6f14399e7785dc783ca5a9047e768a8_job_tag_finished
├── 99c07439f6f14399e7785dc783ca5a9047e768a8.sub
├── backup
├── graph.pb -> ../../../graph.pb
├── result.json
├── result.out
├── run_1660558797.sh
├── task.000000
├── task.000001
├── task.000002
├── task.000003
├── task.000004
├── task.000005
├── task.000006
├── task.000007
├── task.000008
├── task.000009
├── task.000010
├── task.000011
├── task.000012
├── task.000013
├── task.000014
├── task.000015
├── task.000016
├── task.000017
├── task.000018
├── task.000019
└── tmp_log状态方程(EOS)的计算结果显示在 eos_00/results.out 文件中。
(base) ➜ eos_00 cat result.out
conf_dir: /root/1/confs/mp-3034/eos_00
VpA(A^3) EpA(eV)
15.075 -3.2727
15.242 -3.2838
15.410 -3.2935
15.577 -3.3019
15.745 -3.3090
15.912 -3.3148
16.080 -3.3195
16.247 -3.3230
16.415 -3.3254
16.582 -3.3268
16.750 -3.3273
16.917 -3.3268
17.085 -3.3256
17.252 -3.3236
17.420 -3.3208
17.587 -3.3174
17.755 -3.3134
17.922 -3.3087
18.090 -3.3034
18.257 -3.297702.elastic:弹性,如杨氏模量;弹性计算结果显示在elastic_00/results.out文件中。
(base) ➜ elastic_00 cat result.out
/root/1/confs/mp-3034/elastic_00
124.32 55.52 60.56 0.00 0.00 1.09
55.40 125.82 75.02 0.00 0.00 -0.17
60.41 75.04 132.07 0.00 0.00 7.51
0.00 0.00 0.00 53.17 8.44 0.00
0.00 0.00 0.00 8.34 37.17 0.00
1.06 -1.35 7.51 0.00 0.00 34.43
*# Bulk Modulus BV = 84.91 GPa# Shear Modulus GV = 37.69 GPa# Youngs Modulus EV = 98.51 GPa# Poission Ratio uV = 0.31*03.vacancy:空位形成能;vacancy计算结果显示在vacancy_00/results.out文件中。
(base) ➜ vacancy_00 cat result.out
/root/1/confs/mp-3034/vacancy_00
Structure: Vac_E(eV) E(eV) equi_E(eV)
[3, 3, 3]-task.000000: -10.489 -715.867 -705.378
[3, 3, 3]-task.000001: 4.791 -713.896 -718.687
[3, 3, 3]-task.000002: 4.623 -714.064 -718.687- 04.interstitial:间隙形成能;
interstitial计算结果显示在interstitial_00/results.out文件中。
(base) ➜ vacancy_00 cat result.out
/root/1/confs/mp-3034/vacancy_00
Structure: Vac_E(eV) E(eV) equi_E(eV)
[3, 3, 3]-task.000000: -10.489 -715.867 -705.378
[3, 3, 3]-task.000001: 4.791 -713.896 -718.687
[3, 3, 3]-task.000002: 4.623 -714.064 -718.687- 05.surf:表面形成能。
surf计算结果显示在surface_00/results.out文件中。
(base) ➜ surface_00 cat result.out
/root/1/confs/mp-3034/surface_00
Miller_Indices: Surf_E(J/m^2) EpA(eV) equi_EpA(eV)
[1, 1, 1]-task.000000: 1.230 -3.102 -3.327
[1, 1, 1]-task.000001: 1.148 -3.117 -3.327
[2, 2, 1]-task.000002: 1.160 -3.120 -3.327
[2, 2, 1]-task.000003: 1.118 -3.127 -3.327
[1, 1, 0]-task.000004: 1.066 -3.138 -3.327
[2, 1, 2]-task.000005: 1.223 -3.118 -3.327
[2, 1, 2]-task.000006: 1.146 -3.131 -3.327
[2, 1, 1]-task.000007: 1.204 -3.081 -3.327
[2, 1, 1]-task.000008: 1.152 -3.092 -3.327
[2, 1, 1]-task.000009: 1.144 -3.093 -3.327
[2, 1, 1]-task.000010: 1.147 -3.093 -3.327
[2, 1, 0]-task.000011: 1.114 -3.103 -3.327
[2, 1, 0]-task.000012: 1.165 -3.093 -3.327
[2, 1, 0]-task.000013: 1.137 -3.098 -3.327
[2, 1, 0]-task.000014: 1.129 -3.100 -3.327
[1, 0, 1]-task.000015: 1.262 -3.124 -3.327
[1, 0, 1]-task.000016: 1.135 -3.144 -3.327
[1, 0, 1]-task.000017: 1.113 -3.148 -3.327
[1, 0, 1]-task.000018: 1.119 -3.147 -3.327
[1, 0, 1]-task.000019: 1.193 -3.135 -3.327
[2, 0, 1]-task.000020: 1.201 -3.089 -3.327
[2, 0, 1]-task.000021: 1.189 -3.092 -3.327
[2, 0, 1]-task.000022: 1.175 -3.094 -3.327
[1, 0, 0]-task.000023: 1.180 -3.100 -3.327
[1, 0, 0]-task.000024: 1.139 -3.108 -3.327
[1, 0, 0]-task.000025: 1.278 -3.081 -3.327
[1, 0, 0]-task.000026: 1.195 -3.097 -3.327
[2, -1, 2]-task.000027: 1.201 -3.121 -3.327
[2, -1, 2]-task.000028: 1.121 -3.135 -3.327
[2, -1, 2]-task.000029: 1.048 -3.147 -3.327
[2, -1, 2]-task.000030: 1.220 -3.118 -3.327
[2, -1, 1]-task.000031: 1.047 -3.169 -3.327
[2, -1, 1]-task.000032: 1.308 -3.130 -3.327
[2, -1, 1]-task.000033: 1.042 -3.170 -3.327
[2, -1, 0]-task.000034: 1.212 -3.154 -3.327
[2, -1, 0]-task.000035: 1.137 -3.165 -3.327
[2, -1, 0]-task.000036: 0.943 -3.192 -3.327
[2, -1, 0]-task.000037: 1.278 -3.144 -3.327
[1, -1, 1]-task.000038: 1.180 -3.118 -3.327
[1, -1, 1]-task.000039: 1.252 -3.105 -3.327
[1, -1, 1]-task.000040: 1.111 -3.130 -3.327
[1, -1, 1]-task.000041: 1.032 -3.144 -3.327
[1, -1, 1]-task.000042: 1.177 -3.118 -3.327
[2, -2, 1]-task.000043: 1.130 -3.150 -3.327
[2, -2, 1]-task.000044: 1.221 -3.135 -3.327
[2, -2, 1]-task.000045: 1.001 -3.170 -3.327
[1, -1, 0]-task.000046: 0.911 -3.191 -3.327
[1, -1, 0]-task.000047: 1.062 -3.168 -3.327
[1, -1, 0]-task.000048: 1.435 -3.112 -3.327
[1, -1, 0]-task.000049: 1.233 -3.143 -3.327
[1, 1, 2]-task.000050: 1.296 -3.066 -3.327
[1, 1, 2]-task.000051: 1.146 -3.097 -3.327
[1, 0, 2]-task.000052: 1.192 -3.085 -3.327
[1, 0, 2]-task.000053: 1.363 -3.050 -3.327
[1, 0, 2]-task.000054: 0.962 -3.132 -3.327
[1, -1, 2]-task.000055: 1.288 -3.093 -3.327
[1, -1, 2]-task.000056: 1.238 -3.102 -3.327
[1, -1, 2]-task.000057: 1.129 -3.122 -3.327
[1, -1, 2]-task.000058: 1.170 -3.115 -3.327
[0, 0, 1]-task.000059: 1.205 -3.155 -3.327
[0, 0, 1]-task.000060: 1.188 -3.158 -3.327