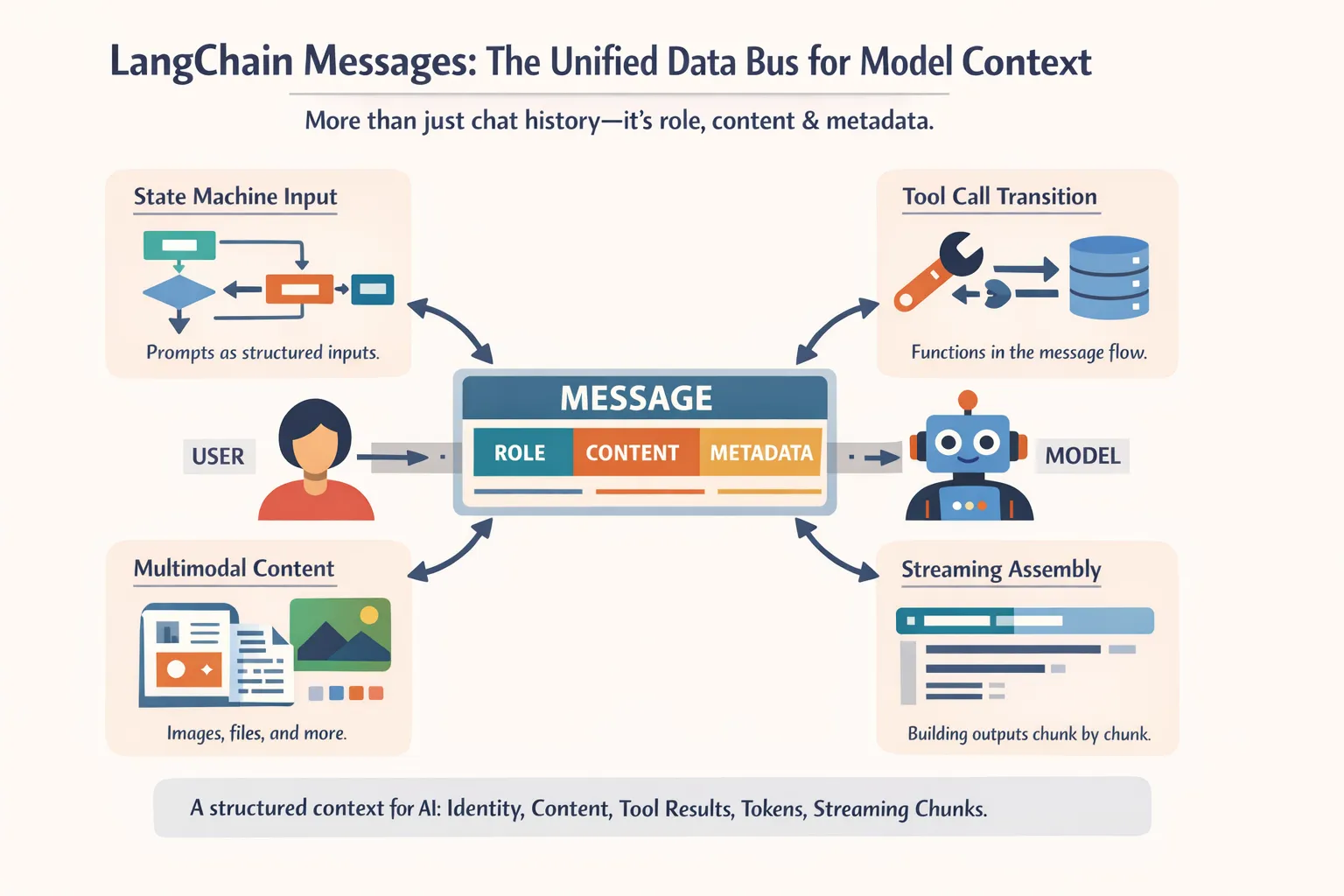
从工程视角看,Messages 不是聊天 UI 的附属物,而是整个模型上下文的统一数据总线。LangChain 在这页文档里把 Message 定义为模型交互的基本单元:里面包含 role、content 和 metadata,并且跨 provider 保持统一接口。也就是说,你传给模型的,不只是“几句对话”,而是一组带身份、内容载体、工具调用结果、token 统计、流式分片信息的结构化上下文。(LangChain Docs)
如果把这个抽象吃透,很多工程决策会更清晰:
- Prompt 不再只是字符串,而是状态机输入
- Tool calling 不再只是“模型调函数”,而是消息流中的一次状态跃迁
- 多模态不再是“另开一个接口”,而是消息内容的一种 block 形式
- 流式输出不只是边打字边显示,而是AIMessageChunk 的逐步拼装过程(LangChain Docs)
一、真正的分界线,不是 Prompt vs Chat,而是“单次生成” vs “可管理上下文”
文档里给了两种最基础的调用方式:
- 直接传字符串:
model.invoke("Write a haiku about spring") - 传消息列表:
model.invoke([SystemMessage(...), HumanMessage(...)])(LangChain Docs)
很多人会把这两者理解为“简洁写法”和“完整版写法”的区别,但从工程上看,真正的分界线是:
- 字符串调用:适合一次性、无状态任务
- 消息调用:适合需要上下文、角色控制、多轮会话、工具调用、多模态输入的任务 (LangChain Docs)
工程建议
如果你的场景满足下面任意一条,就不要再继续用裸字符串:
- 要保留会话历史
- 要加 system instruction
- 要接工具
- 要接图片/PDF/音频
- 要做 token 统计、日志、审计
- 要支持 streaming / agent loop
换句话说,一旦你的应用要上线,Messages 几乎就是默认选项。因为上线应用真正要处理的不是“让模型回答一句话”,而是“持续维护一个可演化的上下文”。
二、SystemMessage 不是“设定人设”,而是你系统边界的第一层防线
文档把 SystemMessage 描述为:用于给模型设定行为方式、角色和回复规范。它既可以是简单指令,也可以是详细 persona。(LangChain Docs)
但在工程里,SystemMessage 的价值远不止“你是一名 Python 专家”。
更实用的理解:SystemMessage 承载三类约束
1. 产品级约束
例如回答风格、输出语言、禁止暴露内部字段、遵守公司话术。
2. 任务级约束
例如“先判断用户意图,再输出 JSON”、“找不到信息时明确说不知道”。
3. 安全级约束
例如不要泄露工具返回的敏感原始数据,不要把内部 trace 回给用户。
一个更接近生产环境的写法
from langchain.chat_models import init_chat_model
from langchain.messages import SystemMessage, HumanMessage
model = init_chat_model("gpt-5-nano")
messages = [
SystemMessage(
content=(
"你是企业内部智能助手。\n"
"回答使用简体中文。\n"
"优先给结论,再给依据。\n"
"如果涉及工具结果,不要直接暴露原始内部字段。\n"
"当信息不足时,明确说明不确定,不要编造。"
)
),
HumanMessage("帮我总结这份故障报告的核心结论")
]
resp = model.invoke(messages)
print(resp.text)一个常见误区
很多团队把大量动态业务上下文也塞进 SystemMessage。这会带来两个问题:
- system prompt 越来越长,成本越来越高
- 业务态和系统态混在一起,后续调试困难
更稳妥的做法是:
SystemMessage放稳定规则- 用户输入放
HumanMessage - 工具结果放
ToolMessage - 模型历史回答放
AIMessage
这样分层以后,日志、回放、裁剪上下文都更容易做。这个分层思路,与 LangChain 对消息类型的划分是完全一致的。(LangChain Docs)
三、HumanMessage 的重点不在“用户说了什么”,而在“用户输入如何被结构化”
文档里提到 HumanMessage 可以包含文本、图片、音频、文件等多模态内容,也支持 name、id 这类元数据。name 是否生效依赖 provider,id 可以用于追踪。(LangChain Docs)
这背后的工程价值很大。
1)id 不是可有可无,它应该进入你的 trace 体系
如果你的应用有这些需求:
- 前端一条消息对应一次后端调用
- 需要排查“这条用户消息为什么触发了某个工具”
- 需要回放线上问题
那就应该主动给 HumanMessage 生成业务 ID,而不是完全依赖 provider 自动返回。
from langchain.messages import HumanMessage
import uuid
msg = HumanMessage(
content="请分析这个工单附件里的错误原因",
id=f"user_msg_{uuid.uuid4().hex}",
name="frontend_user"
)2)多模态输入不要再单独设计一套“附件协议”
这页文档已经给出方向:消息 content 不只可以是字符串,也可以是内容块列表;图像、PDF、音频、视频都能作为 block 塞进同一条消息里。(LangChain Docs)
这意味着在工程上,你可以把用户输入统一建模成:
user_input = {
"text": "...",
"attachments": [...],
"metadata": {...}
}最后映射成一个 HumanMessage,而不是“文本走 messages,附件走另一个接口,OCR 结果再拼第三套上下文”。
统一入口,后续做缓存、审计、重放时会轻松很多。
四、AIMessage 最容易被低估:它不是“模型回复文本”,而是完整响应对象
文档里明确说,model.invoke(...) 返回的是 AIMessage,它除了文本外,还能携带:
contentcontent_blockstool_callsidusage_metadataresponse_metadata(LangChain Docs)
这点很关键,因为很多业务代码还停留在:
answer = model.invoke(messages).content这样写虽然能跑,但你其实把一大半高价值信息都丢了。
工程里应该优先保留的几个字段
1. tool_calls
如果模型要调工具,这就是它的“行动计划”。不是附加信息,而是 agent loop 的核心输入。(LangChain Docs)
2. usage_metadata
这能拿到 token 使用情况,文档示例里包含 input_tokens、output_tokens、total_tokens,甚至细分到 reasoning 等 token 维度。(LangChain Docs)
这在工程上的直接用途:
- 计费
- 限流
- 单请求成本分析
- 上下文裁剪策略优化
- 比较不同 prompt 版本的成本收益
3. response_metadata
这里通常适合留给底层 provider 相关信息,用于日志和调试。(LangChain Docs)
推荐做法:把 AIMessage 原样入库,而不是只存 answer 文本
response = model.invoke(messages)
record = {
"answer_text": response.text,
"message_id": response.id,
"tool_calls": response.tool_calls,
"usage": response.usage_metadata,
"response_metadata": response.response_metadata,
"raw_content": response.content,
}这样以后你才能做:
- 问题回放
- 成本统计
- 工具调度分析
- provider 切换后的兼容性回归
五、Tool Calling 的关键不在“怎么绑定工具”,而在“消息闭环是否完整”
文档给出了典型流程:
- 模型输出一个
AIMessage,其中带tool_calls - 应用执行工具
- 把工具执行结果包装成
ToolMessage - 再把这个
ToolMessage连同前序消息一起送回模型继续推理 (LangChain Docs)
这其实是 LLM 工程里一个非常核心的设计点:
工具调用不是一次函数调用,而是一段消息闭环。
一个最小可运行模式
from langchain.chat_models import init_chat_model
from langchain.messages import HumanMessage, ToolMessage
def get_weather(location: str) -> str:
return f"{location} 晴,23°C"
model = init_chat_model("gpt-5-nano").bind_tools([get_weather])
messages = [HumanMessage("帮我查一下上海天气")]
ai_msg = model.invoke(messages)
messages.append(ai_msg)
for call in ai_msg.tool_calls:
result = get_weather(**call["args"])
messages.append(
ToolMessage(
content=result,
tool_call_id=call["id"],
name=call["name"],
)
)
final_msg = model.invoke(messages)
print(final_msg.text)生产里最容易踩的坑:tool_call_id 对不上
文档强调 ToolMessage.tool_call_id 必须匹配 AIMessage.tool_calls 里的调用 ID。(LangChain Docs)
这意味着:
- 一个 AIMessage 可能触发多个工具调用
- 你不能只按顺序拼结果,必须按 call id 配对
- 并行工具执行时,更要依赖 id 做关联
更进一步:把 artifact 当成“给程序看的结果”,content 当成“给模型看的结果”
文档特别提到 ToolMessage 有一个 artifact 字段:它不会发给模型,但程序可以读取。官方举的例子是检索工具把文档元信息放进 artifact。(LangChain Docs)
这在 RAG 或企业应用里特别有用:
ToolMessage(
content="订单 1024 在 2026-03-10 已完成支付。",
tool_call_id="call_123",
name="query_order",
artifact={
"order_id": 1024,
"db_latency_ms": 18,
"source_table": "payments",
"trace_id": "trace_xxx"
}
)这样你就能做到:
- 模型只看精炼后的工具结果
- 程序保留完整的原始上下文
- 前端还能渲染额外信息,比如来源、耗时、链接
这是非常典型的工程分层:
给模型看的内容要短,给系统保留的数据可以全。
六、content 与 content_blocks:LangChain 真正想解决的是“跨模型格式不统一”
这页文档有一个非常重要但容易被忽略的点:
- message 的
content是宽松类型,可以是字符串,也可以是 provider-native 的列表结构 - LangChain 又提供了
content_blocks,把不同 provider 的内容解析成统一、类型安全的标准表示 content_blocks不是要替代content,而是为了标准化访问内容格式,同时兼容旧代码 (LangChain Docs)
为什么这对工程重要?
因为不同模型厂商对“富内容”定义不一样。
比如文档举例:
- Anthropic 可能返回
thinking - OpenAI 可能返回
reasoning - 但通过
content_blocks,LangChain 能把它们统一成标准化的 reasoning block (LangChain Docs)
这意味着如果你在做:
- 多 provider 切换
- A/B test 不同模型
- 统一日志平台
- 统一前端消息渲染
那你最好不要直接面向 provider 原始格式写业务逻辑,而应该尽量读 content_blocks。
一个更稳妥的处理模式
resp = model.invoke(messages)
for block in resp.content_blocks:
if block["type"] == "text":
handle_text(block["text"])
elif block["type"] == "reasoning":
handle_reasoning(block["reasoning"])一个很实用的细节
文档提到,如果你希望在 LangChain 外部系统里也拿到标准 content block,可以设置环境变量 LC_OUTPUT_VERSION=v1,或者初始化模型时传 output_version="v1"。(LangChain Docs)
这对接外部系统很有帮助,比如:
- 你有自己的消息存储服务
- 你有自己的审计平台
- 你前端消息渲染器不想理解每个 provider 的原始格式
七、多模态设计的关键不是“支持图片”,而是“同一条消息里混合不同载体”
文档明确说明:message content 可以承载图像、PDF、音频、视频等,并展示了 URL、base64、provider-managed file id 等不同形式;同时也提醒,不是所有模型都支持所有文件类型。某些 provider 甚至会要求 PDF 带文件名。(LangChain Docs)
这说明 LangChain 的设计重点并不是“给你一套图片 API”,而是:
把多模态输入统一纳入 Message 体系,而不是把它做成外挂接口。
这对业务系统意味着什么?
1. 一个用户请求可以是“文本 + 图片 + PDF”混合体
例如:
message = {
"role": "user",
"content": [
{"type": "text", "text": "请帮我总结这份 PDF 的第 3 页,并结合这张图解释"},
{"type": "file", "url": "https://example.com/report.pdf", "mime_type": "application/pdf"},
{"type": "image", "url": "https://example.com/chart.png"},
]
}2. 你的服务端应该做“附件到内容块”的统一转换层
不要在 controller 里 if/else 写死:
- 有图片走 vision 接口
- 有 PDF 先 OCR
- 有音频再调 ASR
更合理的架构是先转成统一 message block,再由模型能力和 provider 适配层决定怎么发。
3. 兼容性判断应该前置
文档提醒不同 provider 支持的格式和大小限制不同。(LangChain Docs)
所以生产里最好有一层校验:
- 当前模型是否支持该文件类型
- 文件大小是否超限
- 是用 URL 还是 base64 还是 file_id
- 是否需要额外字段,如 filename
八、Streaming 真正的工程价值,是“渐进构建最终消息对象”
文档里提到 streaming 时会收到 AIMessageChunk,这些 chunk 可以累加合并成完整消息。(LangChain Docs)
这个设计非常值得注意,因为它告诉你:
- 流式输出不是“把字符串一段一段吐出来”这么简单
- 它本质上是“逐步构造一个完整 AIMessage”
为什么这很重要?
因为一旦你的应用支持 tool call、reasoning block、多模态 block,流式过程里就不只是普通文本 token 了,还可能出现:
- 文本块增量
- tool call 参数增量
- server-side tool call chunk
- 其他内容块片段 (LangChain Docs)
工程建议
前端展示时可以按 token 流式刷新,但后端一定要维护一个“最终消息聚合器”:
full_message = None
for chunk in model.stream(messages):
# 实时推送给前端
if chunk.text:
push_to_client(chunk.text)
# 后端聚合完整消息
full_message = chunk if full_message is None else full_message + chunk
# 落库、统计、进入下一轮 tool loop 的应该是 full_message
save(full_message)否则你会遇到这些问题:
- 前端看起来正常,后端却没有完整 AIMessage
- 工具调用参数在流式过程中是碎片 JSON,最后没正确拼好
- token usage / response metadata 无法统一记录
九、消息类型背后,其实是一条标准化的 Agent 状态流
把这页文档串起来看,LangChain 想表达的不只是“有四种消息”:
SystemMessage:定义全局行为边界HumanMessage:承载用户输入AIMessage:承载模型输出、工具决策、usage、元数据ToolMessage:把工具执行结果反馈给模型继续推理 (LangChain Docs)
如果从系统设计角度理解,它们对应的是一个非常清晰的执行流:
SystemMessage
↓
HumanMessage
↓
AIMessage(可能带 tool_calls)
↓
ToolMessage(按 tool_call_id 回填)
↓
AIMessage(基于工具结果继续推理)
这条流最大的价值是:可回放、可裁剪、可观测、可迁移。
- 可回放:问题复现时直接重放消息序列
- 可裁剪:上下文超长时按消息粒度截断或总结
- 可观测:每一步都有结构化记录
- 可迁移:不同 provider 之间有统一抽象层
而文档最后也明确提到,chat models 接受消息序列输入、返回 AIMessage 输出,实际交互往往是无状态的,因此会随着对话增长形成不断扩大的消息列表,这也自然引出“持久化、上下文裁剪、消息总结”等工程问题。(LangChain Docs)
十、一个更像生产代码的消息层设计
如果只基于这页文档,我会建议把 LangChain Messages 这一层设计成下面这样。
1. 统一的消息构建层
负责把前端输入、附件、业务元数据转换成 LangChain message 对象。
2. 统一的消息存储层
存完整 AIMessage / HumanMessage / ToolMessage,不要只存纯文本。
3. 工具执行中间层
专门处理:
- 读取
ai_msg.tool_calls - 分发工具
- 生成
ToolMessage - 关联
tool_call_id
4. 输出适配层
对外可只返回纯文本,但内部保留:
content_blocksusage_metadataresponse_metadataartifact
参考骨架
from langchain.chat_models import init_chat_model
from langchain.messages import SystemMessage, HumanMessage, ToolMessage
def run_turn(user_text: str, history: list, tools: list):
model = init_chat_model("gpt-5-nano")
model = model.bind_tools(tools)
messages = [
SystemMessage(
"你是企业级智能助手。回答简洁,信息不足时明确说明。"
),
*history,
HumanMessage(content=user_text)
]
ai_msg = model.invoke(messages)
messages.append(ai_msg)
if ai_msg.tool_calls:
for call in ai_msg.tool_calls:
tool_name = call["name"]
tool_args = call["args"]
result, artifact = dispatch_tool(tool_name, tool_args)
messages.append(
ToolMessage(
content=result, # 给模型看的
tool_call_id=call["id"], # 关联本次调用
name=tool_name,
artifact=artifact, # 给程序看的
)
)
ai_msg = model.invoke(messages)
messages.append(ai_msg)
return {
"answer": ai_msg.text,
"messages": messages,
"usage": ai_msg.usage_metadata,
"response_metadata": ai_msg.response_metadata,
}这个骨架没有引入别的页面知识,完全是从这页 Messages 文档能推出来的最实用工程落地方式。它利用了文档中强调的几个核心能力:消息序列输入、AIMessage 结构化输出、tool_calls、ToolMessage 回填、usage metadata、artifact 分层。(LangChain Docs)
十一、最容易踩的 6 个坑
1. 只把 Messages 当“聊天历史”
结果是工具结果、token 使用、流式 chunk、附件信息全散落在别处,后续维护很痛苦。文档其实已经说明,消息包含 role、content、metadata,是完整上下文单元。(LangChain Docs)
2. 只取 response.text,不保存 AIMessage
这样你等于主动放弃 tool_calls、usage_metadata、response_metadata。(LangChain Docs)
3. 工具执行后没正确回填 ToolMessage
尤其是 tool_call_id 不匹配,会直接破坏后续推理链路。(LangChain Docs)
4. 直接写死 provider 原始 content 格式
切模型后就容易崩。更稳妥的是尽量消费 content_blocks。(LangChain Docs)
5. 流式输出只做前端展示,不做后端聚合
最后你会有“看起来输出了,但系统里没有完整消息对象”的问题。文档明确说 chunk 可以拼回完整消息。(LangChain Docs)
6. 把工具原始大结果直接塞进 content
更好的做法是:摘要放 content,全量数据放 artifact。(LangChain Docs)
结语:Messages 不是 LangChain 的基础概念,而是 LLM 应用的工程接口
如果只看表面,Messages 像是在教你:
- system/user/assistant/tool 分别怎么写
- content 怎么传字符串或列表
- tool call 怎么回填
但从工程实现看,这页真正讲的是一件更重要的事:
如何把模型交互过程,组织成可组合、可观测、可跨 provider 迁移的结构化消息流。 (LangChain Docs)
所以,做 LangChain 应用时,最好不要把 Messages 当成“Prompt 的另一种写法”。
更准确的理解是:
Messages 是你的上下文协议、工具协议、多模态协议、流式协议,以及运行时审计协议。
当你这样看它,很多设计都会自然变对。